
Ливни, грозы, шквалистый ветер и рекордная жара — этим летом много поводов обсудить погоду. В дата-центрах это не только тема для смол-тока. Природные аномалии и катаклизмы могут сильно повлиять на работу оборудования, если не подумать обо всех рисках заранее. Мы с Романом Бекреневым обобщили наш опыт и рассказываем, как инженеры дата-центров готовятся ко встрече со стихией.
Про стандарты и почему аварии из-за погоды все еще случаются
На первый взгляд кажется, что все погодные проблемы уже учтены в нормативах и правилах. Мы сами не раз рассказывали про разные стандарты проектирования и эксплуатации дата-центров. Вот некоторые:
- стандарты Uptime Institute, которые присваивают те самые Tier;
- международная серия стандартов центров обработки данных EN 50600;
- стандарт телекоммуникационной инфраструктуры для центров обработки данных ANSI/TIA-942 от Ассоциации индустрии телекоммуникаций (TIA);
- российские ГОСТ Р 58811-2020 "Центры обработки данных. Инженерная инфраструктура. Стадии создания" и ГОСТ Р 58812-2020 "Центры обработки данных. Инженерная инфраструктура. Операционная модель эксплуатации. Спецификация".
Разработчики этих стандартов не забывают про оценку природных угроз: экстремальных температур и влажности, ветровой нагрузки, снежной нагрузки, сейсмической активности, затоплений и цунами, риска поражения молнией, пожаров и даже солнечных вспышек, которые ведут к электромагнитным нагрузкам.
Но универсальных правил для защиты от всех природных катастроф в стандартах нет. Во-первых, не для каждого ЦОДа такая защита нужна. В классификации Uptime Institute только дата-центр наивысшего уровня Tier IV является отказоустойчивым, то есть продолжает работу при единичном отказе любого компонента. Для этого важные узлы и пути дистрибуции защищают от физического воздействия. Но даже это не гарантирует полную безопасность при стихийных бедствиях и техногенных катастрофах, авторы требований сами это признают. Так что службе эксплуатации нужно быть готовой к нештатным ситуациям и уметь минимизировать их последствия.
Во-вторых, каждый ЦОД оценивает угрозы в зависимости от вероятности событий в выбранной локации. Uptime Institute призывает внимательнее выбирать место для дата-центра и уделяет особое внимание затоплениям, ураганам, землетрясениям, вулканам. Степень риска таких событий предлагают оценивать по региональной карте наводнений и карте ускорений грунта:

В идеале для снижения риска рекомендуют сразу построить дата-центр в месте с низкой сейсмической активностью, вдали от рек, вулканов, аэропортов и т. п. В реальности же найти идеально безопасное место для дата-центра не всегда возможно. Инженеры по всему миру балансируют между рисками, стоимостью строительства и близостью к конечному потребителю. При этом климат меняется, потопы и торнадо случаются даже там, где их не ждали.
Поэтому важнее становятся не идеальные локации, а “смягчающие меры” и человеческий фактор. Инженерам нужно создать такой комплекс решений, чтобы даже при возникновении аварии не возник “эффект домино” из цепочки новых проблем. Расскажем, как мы выстраиваем эту систему у себя на базе накопленного опыта.
Этапы подготовки на практике
Вот 10 основных стадий, на которых закладывается защита дата-центра. Если позаботиться о безопасности на каждом этапе, то вероятность “эффекта домино” снижается.
1. Проектирование и подбор оборудования по погоде. Проект дата-центра создают по требованиям профильных международных стандартов и по общестроительным нормам. От страны к стране есть своя специфика защиты от стихийных бедствий.
Например, для зданий в Японии заложена дополнительная сейсмоустойчивость, а для стоек и оборудования предусмотрены жесткие крепления на случай землетрясения:
В более близком Казахстане при строительстве используют СНиП РК 2.03-30-2006 “Строительство в сейсмических районах”.
Оборудование для кондиционирования подбирается под местный климат. По стандартам для планирования холодоснабжения рекомендуют учитывать минимальную и максимальную температуру в локации за последние 20 лет. Источником исторических данных часто служат таблицы от ASHRAE — Американского общества инженеров по отоплению, охлаждению и кондиционированию воздуха. Здесь есть данные об экстремальных условиях: аномальной температуре, сильном ветре, влажности. В открытом доступе для примера можно посмотреть данные ASHRAE за 2017 год тут:
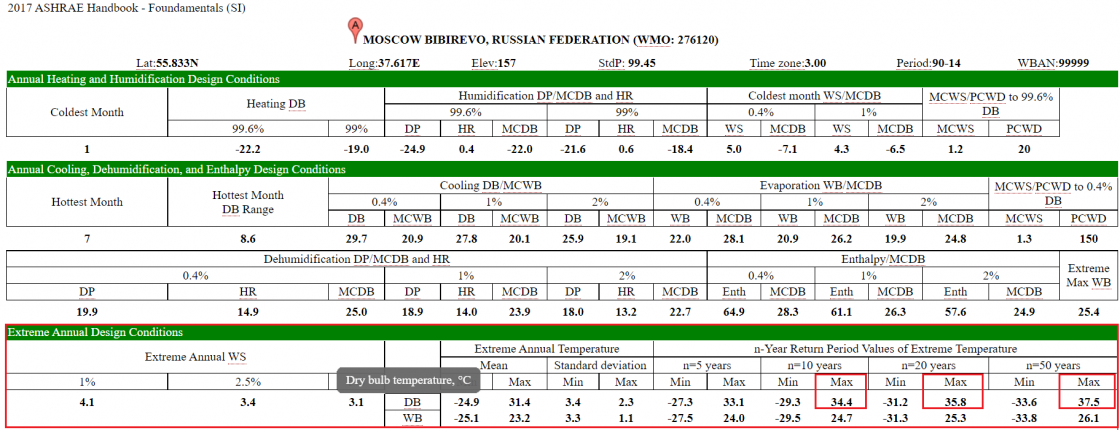
По ASHRAE максимальная температура в Москве по сухому термометру за 20 лет — +35.8 °C
Мы берем промежуток времени больше 20 лет и смотрим дополнительные источники, например, Гидрометцентр. В результате готовы даже к сорокаградусной жаре в Москве и других городах. Способность системы работать в +40 °C обходится ненамного дороже, зато сразу спокойнее жить с перспективой глобального потепления.
В процессе реальной эксплуатации можно столкнуться и с тем, что при определенной силе и направлении ветра на чиллерах происходят захлесты воздуха. Проще говоря, нагретый воздух после одного чиллера попадет на вход другого.
На этот случай мы держим диффузоры: с их помощью воздух выбрасывается выше, без захлеста. А еще они дают всякие бонусы: снижают шум, увеличивают энергоэффективность. Вот пример:

При подборе любого оборудования обращаем внимание на действующие стандарты для электрических систем. Например, требования к нормам напряжения в городской сети отличаются для России и для европейских стран. Поэтому, если мы планируем покупку оборудования в другой стране, стоит сразу подумать про его локализацию. Нужно заранее обсудить адаптацию устройства с вендором или внести изменения во время пуско-наладочных работ. Иначе в самый ответственный момент оборудование откажется работать с “неродными” параметрами электросети.
Во время проектирования продумываем не только основные инженерные системы, но и мониторинг: как будем отслеживать изменения важных параметров. Еще вернемся к этому в пункте 3.
2. Контроль строительства по проекту и приемка. Приемо-сдаточные испытания тоже планируются на этапе проектирования. Затем во время строительства работу на площадке периодически проверяет служба эксплуатации: следит за установкой нового оборудования и параллельно готовит эксплуатационные документы. Дата-центр пока еще пустой, можно спокойно все тестировать и моделировать нештатные ситуации.
На приемке мы сначала проводим автономную проверку отдельных единиц оборудования, потом проверяем подсистемы. Работу каждой подсистемы тестируем в условиях, близких к максимальным паспортным значениям.
Затем переходим к комплексной проверке на уровне всего ЦОДа. Комплексные испытания проводим под нагрузкой: подключаем тепловые пушки и смотрим на работу в боевых условиях. Во время тестов последовательно отключаем одно устройство за другим, имитируем аварии и смотрим, все ли переключения на резервные системы идут по плану.
Подробнее про этапы приемки: Независимая приемка ЦОД.
Приемку и проверку ЦОД на 100% номинальной нагрузки лучше проводить летом. Так мы можем увидеть работу холодоснабжения в условиях жары и обнаружить неявные ошибки. Но не стоит забывать и про испытания зимой: например, при малой загрузке дата-центра можно тоже столкнуться с отказами и в холода.
3. Управление нагрузками в процессе эксплуатации. На случай катастрофы система мониторинга тоже должна быть отказоустойчивой. Например, когда мы планируем конкретный зал, элементы его мониторинга располагаем в другом изолированном помещении. Даже если мы потеряем физический доступ к оборудованию, сможем оценить ситуацию в пострадавшем зале по информации с датчиков.
Когда ЦОД уже введен в эксплуатацию, важно отслеживать перегрузы и сразу на них реагировать. Для этого соблюдаем несколько принципов мониторинга:
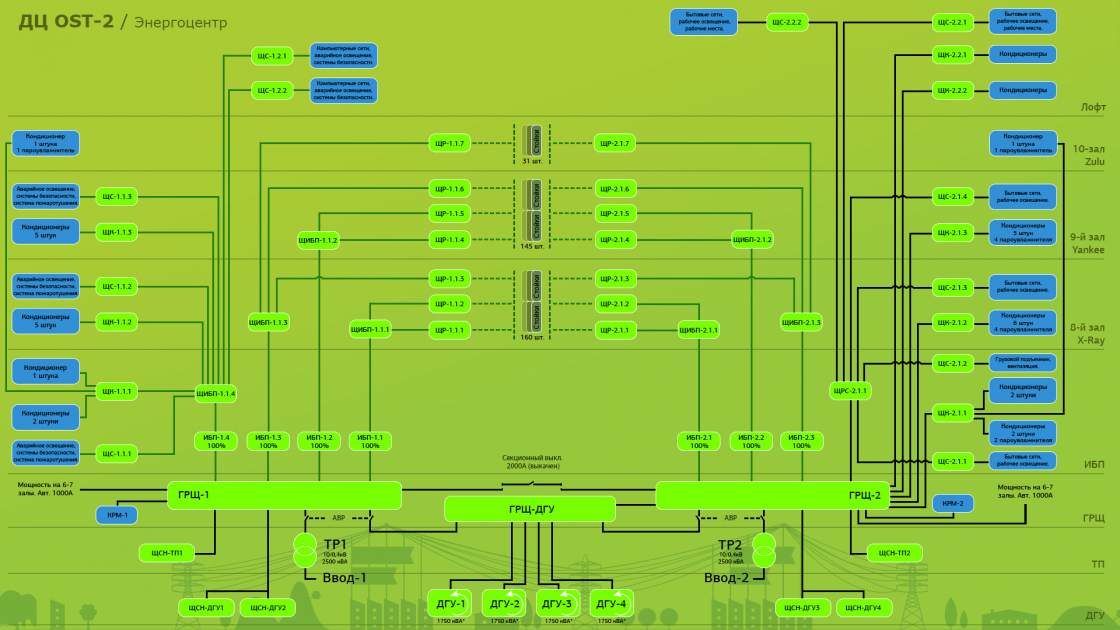
Наблюдаем всю систему целиком. Мы выводим на мониторинг графическую схему инженерной подсистемы и видим не отдельные показатели, а четкую взаимосвязь между компонентами.
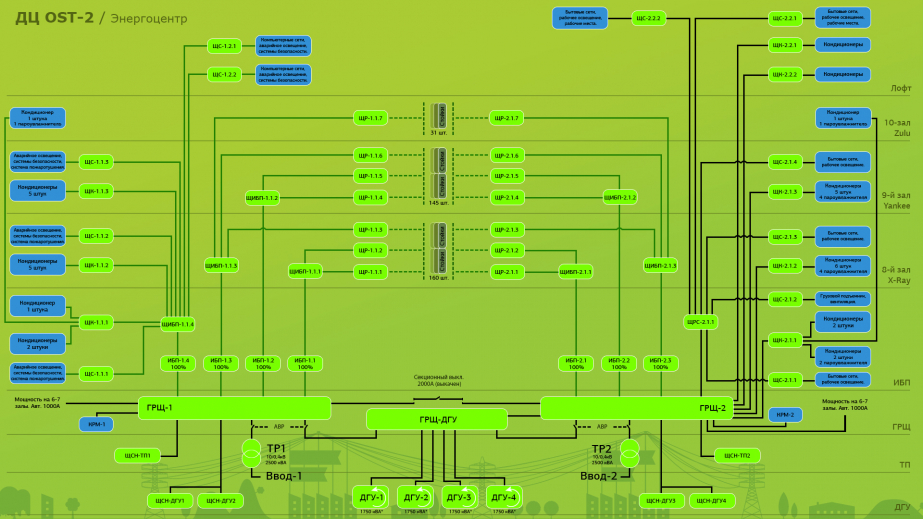
Так проще и быстрее искать причины конкретных сбоев. Например, на схеме зала сразу виден перегрев:
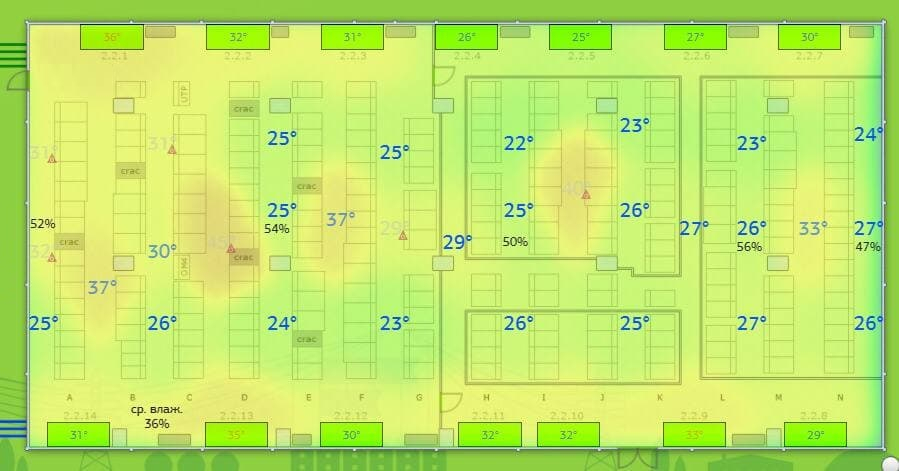
- Ежесекундно опрашиваем критичные узлы вроде дизель-генераторных установок (ДГУ) или источников бесперебойного питания (ИБП). Эти данные нужны не только для быстрого реагирования, но и для истории. Подробная статистика поможет расследовать инциденты.
- Мониторим производные показатели, например, балансировки по фазам и парные нагрузки. Мы вычисляем в системе мониторинга нагрузку по фазам и следим, чтобы перекоса фаз не было, иначе автоматы могут отключиться. Также следим, могут ли резервные элементы принять дополнительную нагрузку во время аварии. Допустим, если пропадет один луч питания из двух, то второй луч должен иметь запас в 50%, чтобы выдержать двойную или парную нагрузку.
Настраиваем комплексные метрики — мониторинг подсистем и даже систем целиком. Например, на одном из объектов есть гликолевый контур состоящий из чиллера, трехходового клапана и насоса.
В мониторинге мы сделали единый алерт, который отслеживает 4 условия одновременно:

Подробнее о наших принципах мониторинга: Мониторинг инженерной инфраструктуры в дата-центре. Часть 2. Система энергоснабжения
4. Регулярные ТО и обходы. Конечно, в самой необходимости техобслуживания обычно убеждать никого не нужно. Но в небольших серверных некоторыми этапами ТО пренебрегают или не учитывают все, что нужно отслеживать.
Слегка капающий кондиционер или требующий замены фильтр — такие мелочи не выглядят угрожающими поначалу, но со временем накопятся и сработают как “снежный ком”. Так что лучше не копить, а фиксировать проблемы во время ежедневных обходов и сразу отправлять их на устранение ответственным специалистам и подрядчикам (ваш кэп).
У нас ежедневные обходы делают сразу 2 группы: дежурные инженеры и инженеры эксплуатации. Получается кросс-проверка наиболее важных частей системы. Так выглядит обход дежурных:
Во время ТО мы опираемся на технологические карты, или процедуры по ведению обслуживающих работ (Methods of Procedures, MOP). Там описываем порядок проведения ТО пошагово, используем эти документы в обучении новых инженеров. Периодически во время ТО мы замечаем какие-то слепые зоны и неочевидные шаги, тогда конкретизируем инструкции.
Отдельный момент про сезонные ТО кондиционеров — важно договориться с подрядчиком о плановом обслуживании до наступления жары. Звучит тоже по-капитански, но это спасает от неожиданностей вроде просроченного договора или большой очереди на обслуживание.
Подробнее о плановой подготовке дата-центра к жаре: Остаться в живых: Чек-лист для подготовки ЦОДа к лету.
5. Регулярные тестовые пуски под нагрузкой с имитацией аварии городского электроснабжения. Некоторые считают, что во время тестовых испытаний достаточно “прогнать” дизель-генераторную установку и убедиться, что она заводится. Мы максимально приближаем ситуацию к реальной и смотрим на поведение всех связанных систем. Заинтересованных лиц заранее предупреждаем об испытаниях, чтобы провести тестовый пуск резерва под реальной нагрузкой.
При аварии городского электроснабжения все системы должны сначала перейти на питание от аккумуляторов на 30—40 секунд, а затем переключиться на ДГУ до устранения аварии. Срок ликвидации последствий мы заранее не знаем, и любая неполадка рискует остаться с нами надолго. Поэтому во время комплексных тестовых испытаний обращаем внимание на все, от важного и до мелочей:
- как работает система автоматического ввода резерва (АВР);
- переключился ли ИБП;
- в каком состоянии аккумуляторные батареи;
- не изменилась ли нагрузка после испытания — признак того, что какое-то устройство могло выключиться и не включиться обратно;
- как реагируют устройства, которые не подключены к ИБП;
- не возникает ли проблем в работе сети, например, не отключился ли wi-fi;
- не отключается ли мониторинг;
- какие статусы у оборудования на мониторинге, доступны ли все контроллеры после перезапуска: у некоторых вспомогательных систем бывают контроллеры с автономным источником питания, например, аккумулятором. Таких маленьких аккумуляторов много по всему ЦОДу, часто даже там, где и не подозревали. Во время испытаний мы обнаруживаем, что какие-то аккумуляторы уже пора заменить.
- остается ли аварийное освещение;
- работает ли телефония.
Подробнее о тестовых пусках: Как тестируют ДГУ в дата-центре.
6. Аварийные инструкции. Помимо MOP в дата-центрах обязательны инструкции на случай нештатных ситуаций, или аварийные эксплуатационные процедуры (Emergency Operating Procedures, EOP). Для описания аварий в EOP мы используем несколько источников. Во-первых, реальную практику — возникшие проблемы во время ТО и комплексных пусков, нештатные ситуации в наших дата-центрах и у коллег. Во-вторых, пока аварий нет, генерируем гипотетические сценарии, вероятность которых в ЦОДе велика.
Для каждого такого случая мы просчитываем все точки отказа: что и где может не сработать. Например, что если при отключении города не сработает ИБП или не запустится ДГУ? Для каждой точки отказа создаем “ветку” аварийного плана. Из всех веток получается целое дерево вариантов с разными условиями.
Во время комплексных испытаний однажды нашли интересную особенность. Есть АВР, которая управляет двумя автоматами. Если на одном из них возникает ошибка, то АВР переключается в ручной режим. В самом плохом сценарии это может привести к тому, что автомат выбьет, а автоматическое переключение на второй луч питания не сработает. В инструкции для инженера мы прописали шаги на этот случай: проверить АВР, сбросить ошибку, запустить второй луч в ручном режиме и вернуть АВР в авторежим (об этом часто забывают).
Этот случай заставил пересмотреть EOP и для других аварий: какая бы крутая автоматика ни была, она может дать сбой, инженеры должны быть готовы к такому.
7. Аварийные тренинги. Любую аварийную инструкцию важно проверить в бою, для этого мы проводим “учения”. Самих дежурных об учениях не предупреждаем, а руководителей оповещаем. Так мы можем проверить уровень взаимодействия в разных критических ситуациях.
Например, мы моделируем ситуацию, что кто-то из руководителей среднего звена окажется не на связи и нужно будет эскалировать проблему выше. Старшего по площадке просим не брать трубку и проигрываем ситуацию, что дежурному нужно позвонить директору. В результате инженеры не боятся позвонить топ-менеджеру если того требует ситуация.
Саму ситуацию тоже делаем максимально близкой к реальности, чтобы Станиславский сказал: “Верю!” Если по сценарию у нас протечка, то наливаем воду и даже останавливаем кондиционер. От дежурных ожидаем такого же полного исполнения роли: при подозрениях на протечку инженер должен прийти на место уже с присоской, чтобы открыть фальшпол. Мы отслеживаем действия сотрудника с момента уведомления об аварии: как он оценивает ситуацию по мониторингу, определяет локацию проблемы, смотрит ли на давление в контуре с хладоносителем и оповещает ли ответственного. Инженер на таких учениях оттачивает навык комплексной оценки проблемы. А мы заодно понимаем, насколько наши дашборды на экране помогают инженерам быстро понять ситуацию.
8. Запасы на случай разных катастроф. Даже если ЦОД напрочь отрежет от внешнего мира, у нас должно быть все для комфортной работы систем и людей. Что держим мы:
- Дизельное топливо: в нашем нефтехранилище всегда есть несколько десятков тонн, сейчас это общая практика во всех более-менее новых ЦОДах.
- Техническую воду, например, если нужно помыть какое-то оборудование при глобальной проблеме. Скажем, авария может произойти на водоканале. Мы рассчитываем нужное количество воды для своих операций: как правило, речь тоже о тоннах.
Запчасти. Помимо стандартных расходников, вроде масла и предохранителей, мы контролируем запасы редких частей, которые быстро не доставить. Держим и неочевидные запчасти, которые хороши на практике, например: для быстрой изоляции протечек в системе кондиционирования храним специальные прорезиненные хомуты (благо, пока не пригодились):

С их помощью можно быстро затянуть прохудившуюся трубу — решение временное, но может пригодиться в экстремальных условиях.
- Запасные ключи, которые лежат отдельно от основного комплекта. Если в ЦОДе все ключи от щитов, кондиционеров и других инженерных систем хранятся централизованно, то дубликаты полезно держать в противоположном крыле. Когда доступ к основному комплекту перекрыт, мы все равно сможем открыть нужные дверцы.
- Системы “самоспас” — если понадобится экстренная эвакуация клиентов и сотрудников.
- Заряженные фонари, рации.
- Еду и питьевую воду.
9. Взаимозаменяемость людей в команде. В карантинном 2020 году из ЦОДа “выгнали” сотрудников, которые могут работать удаленно. Для эксплуатации это была проверка отлаженности процессов: сначала никто не понимал масштабы пандемии, и где-то перестраховка была очень серьезной. Какой опыт помог нам адаптироваться быстро:
- Служба эксплуатации была поделена на группы, которые максимально изолированы друг от друга. Узкие специалисты работали в разных группах на разных площадках. Например, было минимум 2 дизелиста, которые не пересекались между собой, но могли подменить друг друга.
- Наши старшие инженеры в разумной степени многофункциональны. Каждый из них знает инструкции и частично может заменить и холодильщика, и дизелиста (без погружения совсем вглубь конечно). Стараемся развивать побольше таких специалистов.
- Все группы дежурных инженеров знают не только “родную” площадку, но и соседнюю.
- У всех сотрудников уже были настроены удаленные доступы к системам, так что взаимодействие с коллегами на удаленке не вызвало проблем.
Такую же взаимозаменяемость усилили и в отношениях с подрядчиками. Стараемся “дружить” с несколькими подрядчиками на каждую подсистему. Разные варианты предусмотрены на тот случай, если кто-то заболеет или застрянет в пробке и не сможет приехать вовремя.
10. Резервирование для ИТ-систем и офисной инфраструктуры: почты, телефонии и так далее. На опыте мы убедились, что стоит тестировать не только инженерное оборудование. Важно понимать, откуда запитана офисная часть ЦОДа и что с ней будет при аварии. Иначе можно успешно перевести на ДГУ все стойки, но оставить без света и кондиционеров офисных сотрудников. Если забыть про второстепенные системы, можно столкнуться с неочевидными проблемами и в эксплуатации.
В 2012 году на Нью-Йорк обрушился ураган “Сэнди”. Один из дата-центров на Манхэттене держал дизель-генераторы на 17 этаже, а топливные насосы и резервуары с топливом были в подвале. Во время урагана коммунальщики отключили электричество, лифты на 17 этаж перестали работать, и сотрудникам пришлось организовать “топливные бригады”, чтобы переносить дизель пешком по лестнице на 17 этаж.
То же самое справедливо для средств связи с клиентами. Для почтового сервера, сайта и телефона тоже нужен план аварийного восстановления и аварийные тренировки для проверки плана. Этот пункт выходит за пределы эксплуатации инженерной инфраструктуры, но влияет на нашу работу. Так что плотно взаимодействуем с коллегами и проверяем их системы во время учений.
***
Как видно, общей таблетки для борьбы со стихией нет, все складывается из многих нюансов и частностей. Но если на каждом этапе смотреть на проблемы комплексно, не забывать про резервирование и постоянно обмениваться знаниями в команде, то уверенность в защите повышается.