
Сегодня разберем метрики дисковой подсистемы в vSphere. Проблема со стораджем – самая частая причина медленной работы виртуальной машины. Если в случаях с CPU и RAM траблшутинг заканчивается на уровне гипервизора, то при проблемах с диском, возможно, придется разбираться с сетью передачи данных и СХД.
Предмет буду разбирать на примере блочного доступа к СХД, хотя при файловом доступе счетчики примерно те же.
Немного теории
Когда говорят о производительности дисковой подсистемы виртуальных машин, обычно обращают внимание на три связанных друг с другом параметра:
- количество операций ввода/вывода (Input/Output Operations Per Second, IOPS);
- пропускную способность (Throughput);
- задержку операций ввода/вывода (Latency).
Количество IOPS обычно важно для нагрузок произвольного характера (random): доступ к блокам на диске, расположенным в разных местах. Примером такой нагрузки могут послужить базы данных, бизнес-приложения (ERP, CRM) и т.д.
Пропускная способность важна для нагрузок последовательного характера: доступ к блокам, расположенным друг за другом. Например, такую нагрузку могут генерировать файловые сервера (но не всегда) и системы видеонаблюдения.
Пропускная способность связана с количеством операций ввода/вывода следующим образом:
Throughput = IOPS * Block size, где Block size – это размер блока.
Размер блока является довольно важной характеристикой. Современные версии ESXi пропускают блоки размером до 32 767 КБ. Если блок еще больше, он делится на несколько. Не все СХД могут эффективно работать с такими большими блоками, поэтому в Advanced Settings ESXi есть параметр DiskMaxIOSize. С помощью него можно уменьшить максимальный размер блока, пропускаемого гипервизором (подробнее здесь). Рекомендую перед изменением данного параметра проконсультироваться с производителем СХД или хотя бы протестировать изменения на лабораторном стенде.
Большой размер блока может пагубно сказываться на производительности СХД. Даже если количество IOPS и throughput относительно невелики, при большом размере блока могут наблюдаться высокие задержки. Поэтому обращайте внимание на этот параметр.
Latency – самый интересный параметр производительности. Задержка операций ввода/вывода для виртуальной машины складывается из:
- задержки внутри гипервизора (KAVG, Average Kernel MilliSec/Read);
- задержки, которую дают сеть передачи данных и СХД (DAVG, Average Driver MilliSec/Command).
Общая задержка, которая видна в гостевой ОС (GAVG, Average Guest MilliSec/Command), – это сумма KAVG и DAVG.
GAVG и DAVG измеряются, а KAVG рассчитывается: GAVG–DAVG.
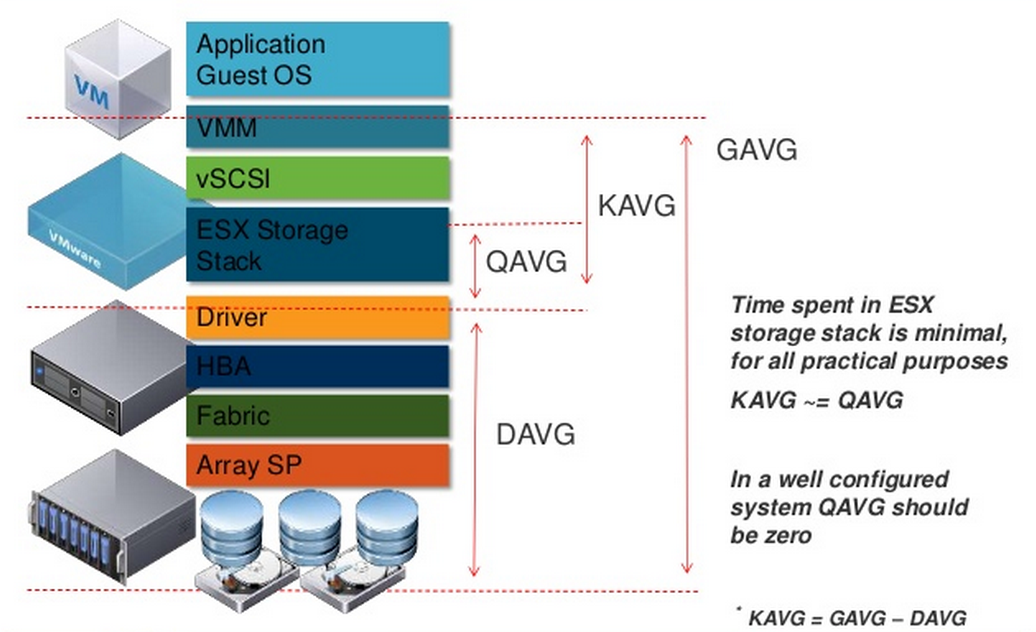
Остановимся подробнее на KAVG. При нормальной работе KAVG должен стремиться к нулю или, по крайней мере, быть сильно меньше, чем DAVG. Единственный известный мне случай, когда KAVG ожидаемо высокий, – ограничение по IOPS на диске ВМ. В таком случае при попытке превышения лимита будет расти KAVG.
Самой значительной составляющей KAVG является QAVG – время в очереди на обработку внутри гипервизора. Остальные составляющие KAVG пренебрежимо малы.
Размер очереди в драйвере дискового адаптера и очереди к лунам имеет фиксированный размер. Для высоконагруженных сред данный размер бывает полезно увеличить. Здесь описано, как увеличить очереди в драйвере адаптера (помните, что одновременно увеличится очередь к лунам). Данная настройка работает, когда с луном работает только одна ВМ, что бывает редко. Если на луне несколько ВМ, необходимо также увеличить параметр Disk.SchedNumReqOutstanding (инструкция здесь). Увеличив очередь, вы уменьшаете QAVG и KAVG соответственно.
Но, опять же, сначала ознакомьтесь с документацией от вендора HBA и протестируйте изменения на лабораторном стенде.
На размер очереди к луну может влиять включение механизма SIOC (Storage I/O Control). Он обеспечивает равномерный доступ к луну со стороны всех серверов кластера за счет динамического изменения очереди к луну на серверах. То есть, если на каком-то из хостов работает ВМ, которая требует непропорционально много производительности (noisy neighbor VM), SIOC уменьшает длину очереди к луну на данном хосте (DQLEN). Подробнее здесь.
С KAVG разобрались, теперь немного о DAVG. Тут все просто: DAVG – это задержка, которую вносит внешняя среда (сеть передачи данных и СХД). В любой современной и не очень СХД есть свои счетчики производительности. Для анализа проблем с DAVG имеет смысл смотреть на них. Если же со стороны ESXi и СХД все нормально, проверяйте сеть передачи данных.
Чтобы не было проблем с производительностью, выбирайте правильную Path Selection Policy (PSP) для вашей СХД. Практически все современные СХД поддерживают PSP Round-Robin (с ALUA, Asymmetric Logical Unit Access, или без). Данная политика позволяет использовать все доступные пути к СХД. В случае с ALUA используются только пути до контроллера, который владеет луном. Не для всех СХД на ESXi есть дефолтные правила, которые устанавливают политику Round-Robin. Если для вашего СХД правила нет, используйте плагин от производителя СХД, который создаст соответствующее правило на всех хостах кластера, или создайте правило самостоятельно. Подробности здесь.
Также часть производителей СХД рекомендуют менять количество IOPS на путь со стандартного значения 1000 на 1. В нашей практике это позволяло «выжать» из СХД больше производительности и значительно сократить время, которое требуется на failover в случае выхода из строя или обновления контроллеров. Сверьтесь с рекомендациями вендора, и если противопоказаний нет, то попробуйте изменить данный параметр. Подробности здесь.
Основные счетчики производительности дисковой подсистемы виртуальной машины
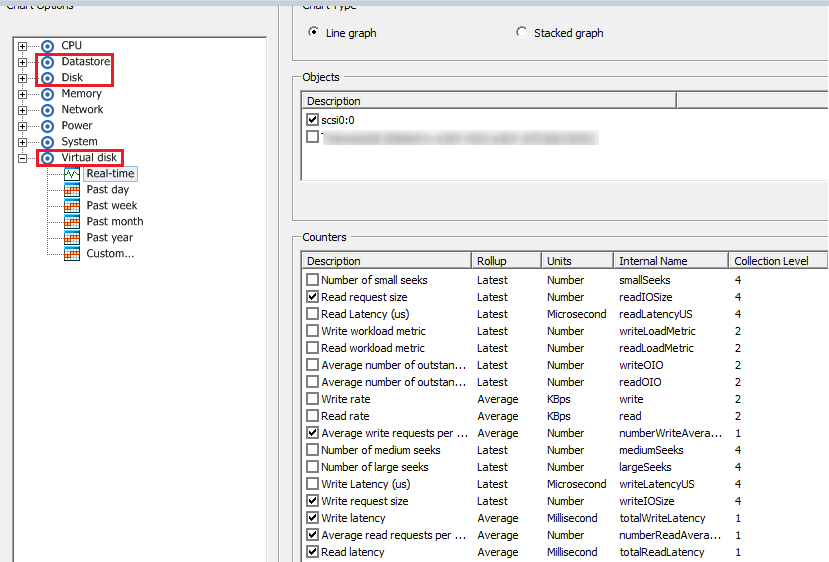
Счетчики производительности дисковой подсистемы в vCenter собраны в разделах Datastore, Disk, Virtual Disk:
В разделе Datastore находятся метрики по дисковым хранилищам vSphere (датасторам), на которых лежат диски ВМ. Здесь вы найдете стандартные счетчики по:
- IOPS’ам (Average read/write requests per second),
- пропускной способности (Read/Write rate),
- задержкам (Read/Write/Highest latency).
Из названий счетчиков в принципе все понятно. Еще раз обращу внимание, что здесь статистика не по конкретной ВМ (или диску ВМ), а общая по всему датастору. На мой взгляд, данную статистику удобнее смотреть в ESXTOP, хотя бы исходя из того, что минимальный период измерения там 2 секунды.
В разделе Disk находятся метрики по блочным устройствам, которые используются ВМ. Тут есть счетчики по IOPS типа summation (количество операций ввода/вывода за период измерения) и несколько счетчиков, относящихся к блочному доступу (Commands aborted, Bus resets). Данную информацию, на мой взгляд, также удобнее смотреть в ESXTOP.
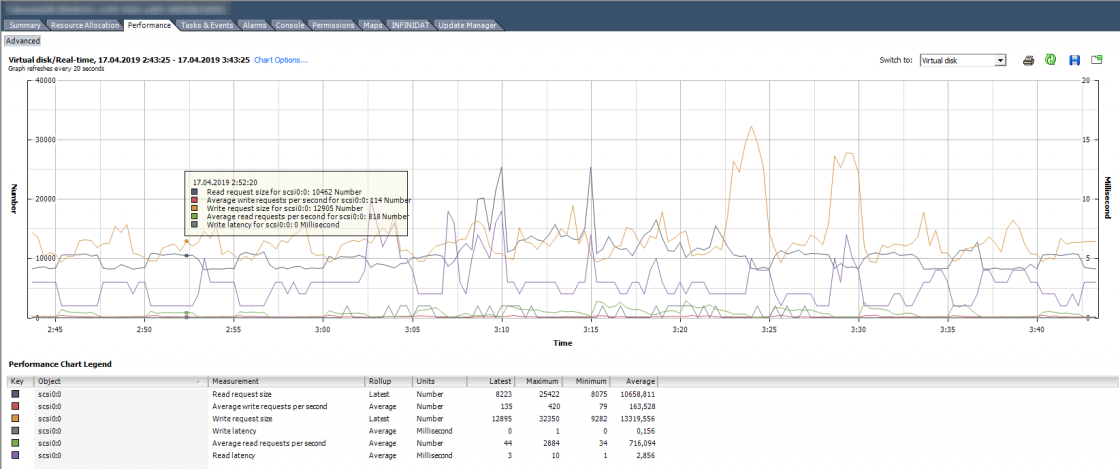
Раздел Virtual Disk – самый полезный с точки зрения поиска проблем производительности дисковой подсистемы ВМ. Здесь можно посмотреть производительность по каждому виртуальному диску. Именно эта информация нужна, чтобы понять, есть ли проблема у конкретной виртуальной машины. Помимо стандартных счетчиков количества операций ввода/вывода, объема чтения/записи и задержек, в данном разделе присутствуют полезные счетчики, которые показывают размер блока: Read/Write request size.
На картинки ниже график производительности диска ВМ, на котором можно увидеть количество IOPS, задержки и размер блока.
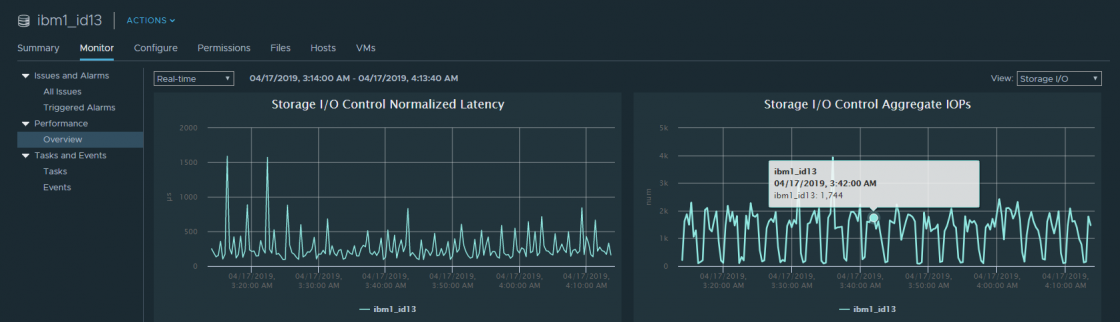
Также метрики производительности можно посмотреть по всему датастору, если включен SIOC. Здесь представлена базовая информация по средней Latency и IOPS’ам. По умолчанию данную информацию можно посмотреть только в реальном времени.
ESXTOP
В ESXTOP несколько экранов, на которых представлена информация по дисковой подсистеме хоста в целом, отдельным виртуальным машинам и их дискам.
Начнем с информации по виртуальным машинам. Экран “Disk VM” вызывается клавишей “v”:
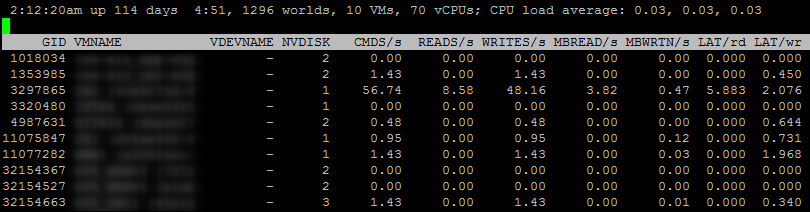
NVDISK – это количество дисков ВМ. Чтобы посмотреть информацию по каждому диску, нажмите “e” и введите GID интересующей ВМ.
Значение остальных параметров на данном экране понятно из их названий.
Еще один полезный при поиске проблем экран – Disk adapter. Вызывается клавишей “d” (на картинке ниже выбраны поля A,B,C,D,E,G):

NPTH – количество путей к лунам, которые видны с данного адаптера. Чтобы получить информацию по каждому пути на адаптере, нажмите “e” и введите название адаптера:
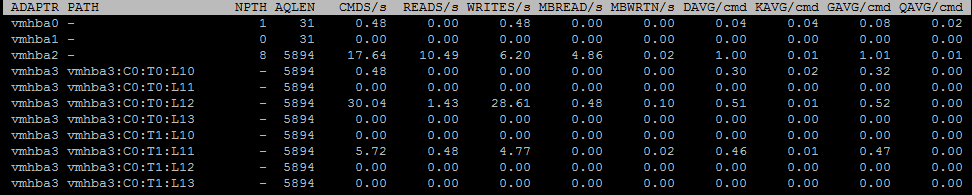
AQLEN – максимальный размер очереди на адаптере.
Также на этом экране представлены счетчики задержек, о которых я рассказывал выше: KAVG/cmd, GAVG/cmd, DAVG/cmd, QAVG/cmd.
На экране Disk device, который вызывается клавишей “u”, представлена информация по отдельным блочным устройствам – лунам (на картинке ниже выбраны поля A, B, F, G, I). Здесь можно увидеть состояние очереди к лунам.

DQLEN – размер очереди для блочного устройства.
ACTV – количество команд ввода/вывода в ядре ESXi.
QUED – количество команд ввода/вывода в очереди.
%USD – ACTV / DQLEN × 100%.
LOAD – (ACTV + QUED) / DQLEN.
Если %USD высокий, стоит рассмотреть возможность увеличения очереди. Чем больше команд в очереди, тем выше QAVG и, соответственно, KAVG.
Также на экране Disk device можно посмотреть, работает ли на СХД VAAI (vStorage API for Array Integration). Для этого нужно выбрать поля A и O.
Механизм VAAI позволяет перенести часть работы из гипервизора непосредственно на СХД, например, зануление, копирование блоков или блокировки.

Как видно на картинке выше, на данной СХД VAAI работает: активно используются примитивы Zero и ATS.
Советы по оптимизации работы с дисковой подсистемой на ESXi
- Обращайте внимание на размер блока.
- Устанавливайте оптимальный размер очереди на HBA.
- Не забывайте включать SIOC на датасторах.
- Выбирайте PSP в соответствии с рекомендациями производителя СХД.
- Убедитесь, что VAAI работает.
http://www.yellow-bricks.com/2011/06/23/disk-schednumreqoutstanding-the-story/
http://www.yellow-bricks.com/2009/09/29/whats-that-alua-exactly/
http://www.yellow-bricks.com/2019/03/05/dqlen-changes-what-is-going-on/
https://www.codyhosterman.com/2017/02/understanding-vmware-esxi-queuing-and-the-flasharray/
https://www.codyhosterman.com/2018/03/what-is-the-latency-stat-qavg/
https://kb.vmware.com/s/article/1267
https://kb.vmware.com/s/article/1268
https://kb.vmware.com/s/article/1027901
https://kb.vmware.com/s/article/2069356
https://kb.vmware.com/s/article/2053628