
В этой статье поговорим про счетчики производительности оперативной памяти (RAM) в vSphere.
Вроде бы с памятью все более однозначно, чем с процессором: если на ВМ возникают проблемы с производительностью, их сложно не заметить. Зато если они появляются, справиться с ними гораздо сложнее. Но обо всем по порядку.
Немного теории
Оперативная память виртуальных машин берется из памяти сервера, на которых работают ВМ. Это вполне очевидно:). Если оперативной памяти сервера не хватает для всех желающих, ESXi начинает применять техники оптимизации потребления оперативной памяти (memory reclamation techniques). В противном случае операционные системы ВМ падали бы с ошибками доступа к ОЗУ. Какие техники применять ESXi решает в зависимости от загруженности оперативной памяти:
| Состояние памяти | Граница | Действия |
|---|---|---|
| High | 400% от minFree | После достижения верхней границы, большие страницы памяти разбиваются на маленькие (TPS работает в стандартном режиме). |
| Clear | 100% от minFree | Большие страницы памяти разбиваются на маленькие, TPS работает принудительно. |
| Soft | 64% от minFree | TPS + Balloon |
| Hard | 32% от minFree | TPS + Compress + Swap |
| Low | 16% от minFree | Compress + Swap + Block |
minFree — это оперативная память, необходимая для работы гипервизора.
До ESXi 4.1 включительно minFree по умолчанию было фиксированным — 6% от объема оперативной памяти сервера (процент можно было поменять через опцию Mem.MinFreePct на ESXi). В более поздних версиях из-за роста объемов памяти на серверах minFree стало рассчитываться исходя из объема памяти хоста, а не как фиксированное процентное значение. Значение minFree (по умолчанию) считается следующим образом:
| Процент памяти, резервируемый для minFree | Диапазон памяти |
|---|---|
| 6% | 0-4 Гбайт |
| 4% | 4-12 Гбайт |
| 2% | 12-28 Гбайт |
| 1% | Оставшаяся память |
Например, для сервера со 128 Гбайт RAM значение MinFree будет таким:
MinFree = 245,76 + 327,68 + 327,68 + 1024 = 1925,12 Мбайт = 1,88 Гбайт
Фактическое значение может отличаться на пару сотен МБайт, это зависит от сервера и оперативной памяти.
| Процент памяти, резервируемый для minFree | Диапазон памяти | Значение для 128 Гбайт |
|---|---|---|
| 6% | 0-4 Гбайт | 245,76 Мбайт |
| 4% | 4-12 Гбайт | 327,68 Мбайт |
| 2% | 12-28 Гбайт | 327,68 Мбайт |
| 1% | Оставшаяся память (100 Гбайт) | 1024 Мбайт |
Обычно для продуктивных стендов нормальным можно считать только состояние High. Для стендов для тестирования и разработки приемлемыми могут быть состояния Clear/Soft. Если оперативной памяти на хосте осталось менее 64% MinFree, то у ВМ, работающих на нем, точно наблюдаются проблемы с производительностью.
В каждом состоянии применяются определенные memory reclamation techniques начиная с TPS, практически не влияющего на производительность ВМ, заканчивая Swapping’ом. Расскажу про них подробнее.
Transparent Page Sharing (TPS). TPS — это, грубо говоря, дедупликация страниц оперативной памяти виртуальных машин на сервере.
ESXi ищет одинаковые страницы оперативной памяти виртуальных машин, считая и сравнивая hash-сумму страниц, и удаляет дубликаты страниц, заменяя их ссылками на одну и ту же страницу в физической памяти сервера. В результате потребление физической памяти снижается и можно добиться некоторой переподписки по памяти практически без снижения производительности.
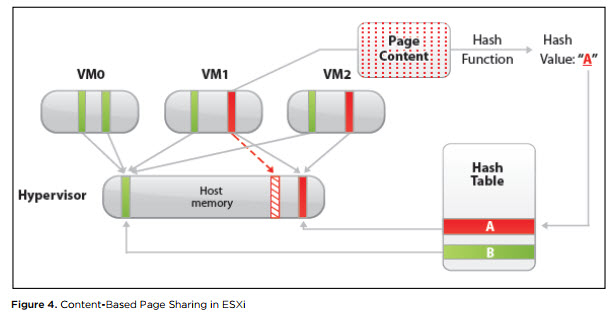
Данный механизм работает только для страниц памяти размером 4 Кбайт (small pages). Страницы размером 2 МБайт (large pages) гипервизор дедуплицировать даже не пытается: шанс найти одинаковые страницы такого размера не велик.
По умолчанию ESXi выделяет память большим страницам. Разбивание больших страниц на маленькие начинается при достижении порога состояния High и происходит принудительно, когда достигается состояние Clear (см. таблицу состояний гипервизора).
Если же вы хотите, чтобы TPS начинал работу, не дожидаясь заполнения оперативной памяти хоста, в Advanced Options ESXi нужно установить значение “Mem.AllocGuestLargePage” в 0 (по умолчанию 1). Тогда выделение больших страниц памяти для виртуальных машин будет отключено.
С декабря 2014 во всех релизах ESXi TPS между ВМ по умолчанию отключен, так как была найдена уязвимость, теоретически позволяющая получить из одной ВМ доступ к оперативной памяти другой ВМ. Подробности тут. Информация про практическую реализацию эксплуатации уязвимости TPS мне не встречалось.
Политика TPS контролируется через advanced option “Mem.ShareForceSalting” на ESXi:
0 — Inter-VM TPS. TPS работает для страниц разных ВМ;
1 – TPS для ВМ с одинаковым значением “sched.mem.pshare.salt” в VMX;
2 (по умолчанию) – Intra-VM TPS. TPS работает для страниц внутри ВМ.
Однозначно имеет смысл выключать большие страницы и включать Inter-VM TPS на тестовых стендах. Также это можно использовать для стендов с большим количеством однотипных ВМ. Например, на стендах с VDI экономия физической памяти может достигать десятков процентов.
Memory Ballooning. Ballooning уже не такая безобидная и прозрачная для операционной системы ВМ техника, как TPS. Но при грамотном применении с Ballooning’ом можно жить и даже работать.
Вместе с Vmware Tools на ВМ устанавливается специальный драйвер, называемый Balloon Driver (он же vmmemctl). Когда гипервизору начинает не хватать физической памяти и он переходит в состояние Soft, ESXi просит ВМ вернуть неиспользуемую оперативную память через этот Balloon Driver. Драйвер в свою очередь работает на уровне операционной системы и запрашивает свободную память у нее. Гипервизор видит, какие страницы физической памяти занял Balloon Driver, забирает память у виртуальной машины и возвращает хосту. Проблем с работой ОС не возникает, так как на уровне ОС память занята Balloon Driver’ом. По умолчанию Balloon Driver может забрать до 65% памяти ВМ.
Если на ВМ не установлены VMware Tools или отключен Ballooning (не рекомендую, но есть KB:), гипервизор сразу переходит к более жестким техникам отъема памяти. Вывод: следите, чтобы VMware Tools на ВМ были.
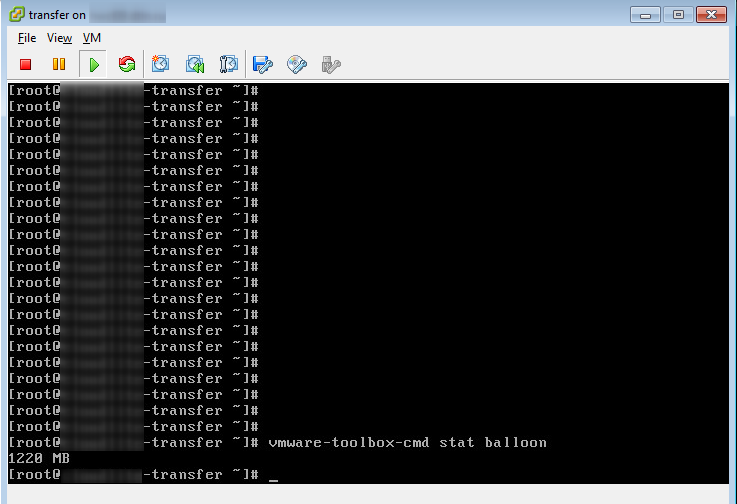
Работу Balloon Driver’а можно проверить из ОС через VMware Tools
Memory Compression. Данная техника применяется, когда ESXi доходит до состояния Hard. Как следует из названия, ESXi пытается сжать 4 Кбайт страницы оперативной памяти до 2 Кбайт и таким образом освободить немного места в физической памяти сервера. Данная техника значительно увеличивает время доступа к содержимому страниц оперативной памяти ВМ, так как страницу надо предварительно разжать. Иногда не все страницы удается сжать и сам процесс занимает некоторое время. Поэтому данная техника на практике не очень эффективна.
Memory Swapping. После недолгой фазы Memory Compression ESXi практически неизбежно (если ВМ не уехали на другие хосты или не выключились) переходит к Swapping’у. А если памяти осталось совсем мало (состояние Low), то гипервизор также перестает выделять ВМ страницы памяти, что может вызвать проблемы в гостевых ОС ВМ.
Вот как работает Swapping. При включении виртуальной машины для нее создается файл с расширением .vswp. По размеру он равен незарезервированной оперативной памяти ВМ: это разница между сконфигурированной и зарезервированной памятью. При работе Swapping’а ESXi выгружает страницы памяти виртуальной машины в этот файл и начинает работать с ним вместо физической памяти сервера. Разумеется, такая такая “оперативная” память на несколько порядков медленнее настоящей, даже если .vswp лежит на быстром хранилище.
В отличие от Ballooning’а, когда у ВМ отбираются неиспользуемые страницы, при Swapping’e на диск могут переехать страницы, которые активно используются ОС или приложениями внутри ВМ. В результате производительность ВМ падает вплоть до подвисания. ВМ формально работает и ее как минимум можно правильно отключить из ОС. Если вы будете терпеливы ;)
Если ВМ ушли в Swap — это нештатная ситуация, которую по возможности лучше не допускать.
Основные счетчики производительности памяти виртуальной машины
Вот мы и добрались до главного. Для мониторинга состояния памяти в ВМ есть следующие счетчики:
Active — показывает объем оперативной памяти (Кбайт), к которому ВМ получила доступ в предыдущий период измерения.
Usage — то же, что Active, но в процентах от сконфигурированной оперативной памяти ВМ. Рассчитывается по следующей формуле: active ÷ virtual machine configured memory size.
Высокий Usage и Active, соответственно, не всегда является показателем проблем производительности ВМ. Если ВМ агрессивно использует память (как минимум, получает к ней доступ), это не значит, что памяти не хватает. Скорее это повод посмотреть, что происходит в ОС.
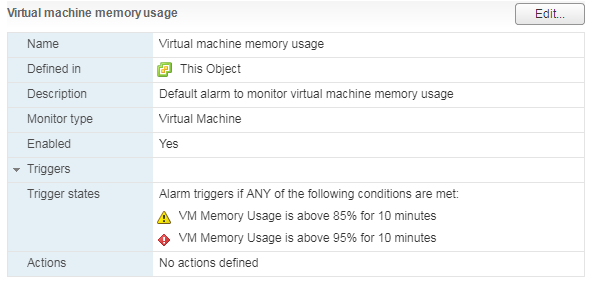
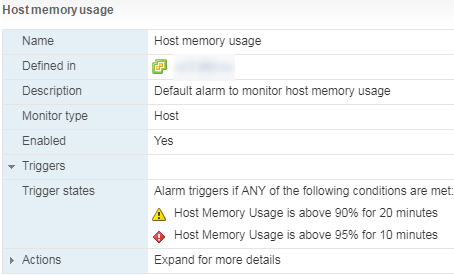
Есть стандартный Alarm по Memory Usage для ВМ:
Shared — объем оперативной памяти ВМ, дедуплицированной с помощью TPS (внутри ВМ или между ВМ).
Granted — объем физической памяти хоста (Кбайт), который был отдан ВМ. Включает Shared.
Consumed (Granted — Shared) — объем физической памяти (Кбайт), которую ВМ потребляет с хоста. Не включает Shared.
Если часть памяти ВМ отдается не из физической памяти хоста, а из swap-файла или память отобрана у ВМ через Balloon Driver, данный объем не учитывается в Granted и Consumed.
Высокие значения Granted и Consumed — это совершенно нормально. Операционная система постепенно забирает память у гипервизора и не отдает обратно. Со временем у активно работающей ВМ значения данных счетчиков приближается к объему сконфигурированной памяти, и там остаются.
Zero — объем оперативной памяти ВМ (Кбайт), который содержит нули. Такая память считается гипервизором свободной и может быть отдана другим виртуальным машинам. После того, как гостевая ОС получила записала что-либо в зануленную память, она переходит в Consumed и обратно уже не возвращается.
Reserved Overhead — объем оперативной памяти ВМ, (Кбайт) зарезервированный гипервизором для работы ВМ. Это небольшой объем, но он обязательно должен быть в наличии на хосте, иначе ВМ не запустится.
Balloon — объем оперативной памяти (Кбайт), изъятой у ВМ с помощью Balloon Driver.
Compressed — объем оперативной памяти (Кбайт), которую удалось сжать.
Swapped — объем оперативной памяти (Кбайт), которая за неимением физической памяти на сервере переехала на диск.
Balloon и остальные счетчики memory reclamation techniques равны нулю.
Вот так выглядит график со счетчиками Memory нормально работающей ВМ со 150 ГБ оперативной памяти.

На графике ниже у ВМ явные проблемы. Под графиком видно, что для данной ВМ были использованы все описанные техники работы с оперативной памятью. Balloon для данной ВМ сильно больше, чем Consumed. По факту ВМ скорее мертва, чем жива.

ESXTOP
Как и с CPU, если хотим оперативно оценить ситуацию на хосте, а также ее динамику с интервалом до 2 секунд, стоит воспользоваться ESXTOP.
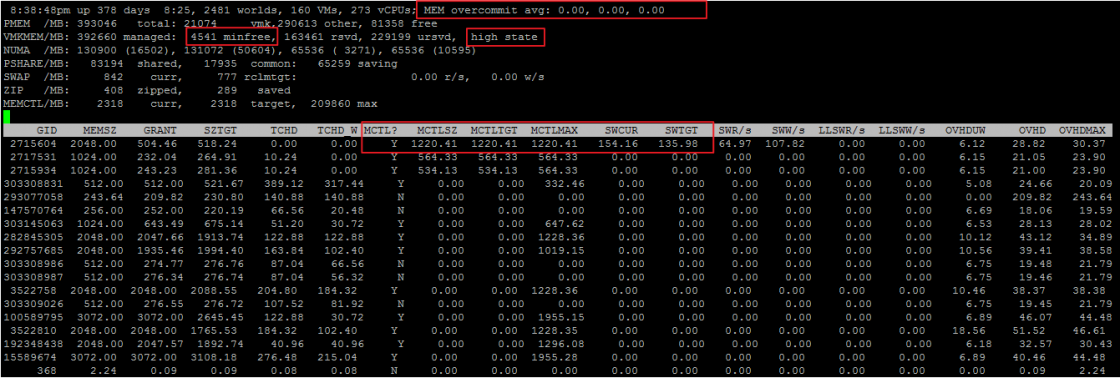
Экран ESXTOP по Memory вызывается клавишей «m» и выглядит следующим образом (выбраны поля B,D,H,J,K,L,O):
Интересными для нас будут следующие параметры:
Mem overcommit avg — среднее значение переподписки по памяти на хосте за 1, 5 и 15 минут. Если выше нуля, то это повод посмотреть, что происходит, но не всегда показатель наличия проблем.
В строках PMEM/MB и VMKMEM/MB — информация о физической памяти сервера и памяти доступной VMkernel. Из интересного здесь можно увидеть значение minfree (в МБайт), состояние хоста по памяти (в нашем случае, high).
В строке NUMA/MB можно увидеть распределение оперативной памяти по NUMA-нодам (сокетам). В данном примере распределение неравномерное, что в принципе не очень хорошо.
Далее идет общая статистика по серверу по memory reclamation techniques:
PSHARE/MB — это статистика TPS;
SWAP/MB — статистика использования Swap;
ZIP/MB — статистика компрессии страниц памяти;
MEMCTL/MB — статистика использования Balloon Driver.
По отдельным ВМ нас может заинтересовать следующая информация. Имена ВМ я скрыл, чтобы не смущать аудиторию:). Если метрика ESXTOP аналогична счетчику в vSphere, привожу соответствующий счетчик.
MEMSZ — объем памяти, сконфигурированный на ВМ (МБ).
MEMSZ = GRANT + MCTLSZ + SWCUR + untouched.
GRANT — Granted в МБайт.
TCHD — Active в МБайт.
MCTL? — установлен ли на ВМ Balloon Driver.
MCTLSZ — Balloon в МБайт.
MCTLGT — объем оперативной памяти (МБайт), который ESXi хочет изъять у ВМ через Balloon Driver (Memctl Target).
MCTLMAX — максимальный объем оперативной памяти (МБайт), который ESXi может изъять у ВМ через Balloon Driver.
SWCUR — текущий объем оперативной памяти (МБайт), отданный ВМ из Swap-файла.
SWGT — объем оперативной памяти (МБайт), который ESXi хочет отдавать ВМ из Swap-файла (Swap Target).
Также через ESXTOP можно посмотреть более подробную информацию про NUMA-топологию ВМ. Для этого нужно выбрать поля D,G:
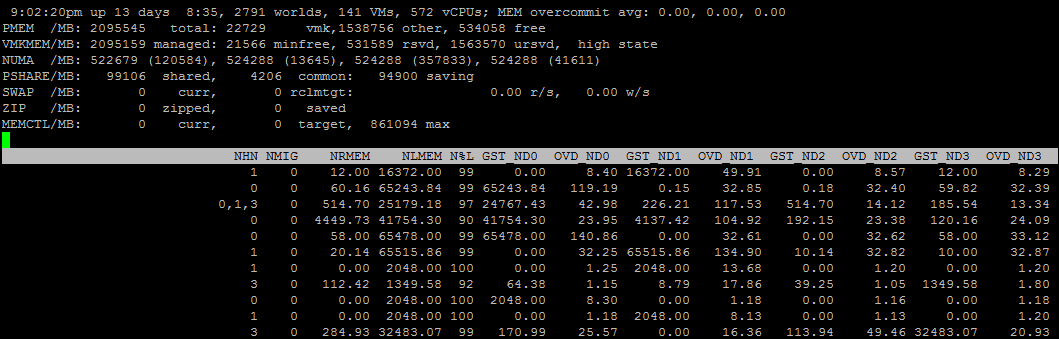
NHN – NUMA узлы, на которых расположена ВМ. Здесь можно сразу заметить wide vm, которые не помещаются на один NUMA узел.
NRMEM – сколько мегабайт памяти ВМ берет с удаленного NUMA узла.
NLMEM – сколько мегабайт памяти ВМ берет с локального NUMA узла.
N%L – процент памяти ВМ на локальном NUMA узле (если меньше 80% — могут возникнуть проблемы с производительностью).
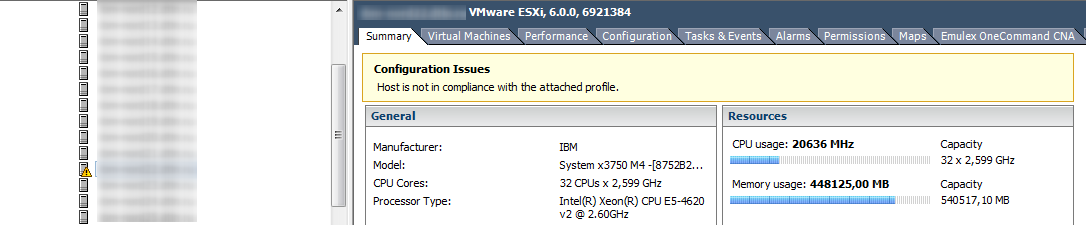
Memory на гипервизоре
Если счетчики CPU по гипервизору обычно не представляют особого интереса, то с памятью ситуация обратная. Высокий Memory Usage на ВМ не всегда говорит о наличие проблемы с производительностью, а вот высокий Memory Usage на гипервизоре, как раз запускает работу техник управления памятью и вызывает проблемы с производительностью ВМ. За алармами Host Memory Usage надо следить и не допускать попадания ВМ в Swap.
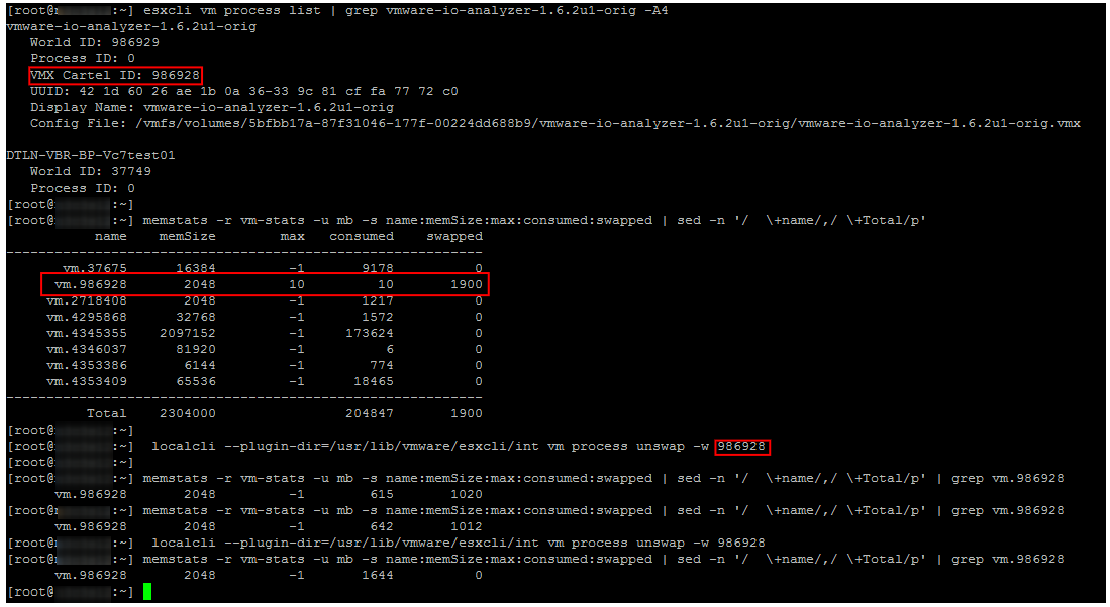
Unswap
Если ВМ попала в Swap, ее производительность сильно снижается. Следы Ballooning’а и компрессии быстро исчезают после появления свободной оперативной памяти на хосте, а вот возвращаться из Swap в оперативную память сервера виртуальная машина совсем не торопится.
До версии ESXi 6.0 единственным надежным и быстрым способ вывода ВМ из Swap была перезагрузка (если точнее выключение/включение контейнера). Начиная с ESXi 6.0 появился хотя и не совсем официальный, но рабочий и надежный способ вывести ВМ из Swap. На одной из конференций мне удалось пообщаться с одним из инженеров VMware, отвечающим за CPU Scheduler. Он подтвердил, что способ вполне рабочий и безопасный. В нашем опыте проблем с ним также замечено не было.
Собственно команды для вывода ВМ из Swap описал Duncan Epping. Не буду повторять подробное описание, просто приведу пример ее использования. Как видно на скриншоте, через некоторое время после выполнения указанной команд Swap на ВМ исчезает.
Советы по управлению оперативной памятью на ESXi
Напоследок приведу несколько советов, которые помогут вам избежать проблем с производительностью ВМ из-за оперативной памяти:
- Не допускайте переподписки по оперативной памяти в продуктивных кластерах. Желательно всегда иметь ~20-30% свободной памяти в кластере, чтобы у DRS ( и у администратора) было пространство для маневра, и при миграции ВМ не ушли в Swap. Также не забывайте про запас для отказоустойчивости. Неприятно, когда при выходе из строя одного сервера и перезагрузке ВМ с помощью HA часть машин еще и уходит в Swap.
- В инфраструктурах с высокой консолидацией старайтесь НЕ создавать ВМ с памятью больше половины памяти хоста. Это опять же поможет DRS’у без проблем распределять виртуальные машины по серверам кластера. Это правило, разумеется, не универсальное :).
- Следите за Host Memory Usage Alarm.
- Не забывайте ставить на ВМ VMware Tools и не выключайте Ballooning.
- Рассмотрите возможность включения Inter-VM TPS и выключения Large Pages в средах с VDI и тестовых средах.
- Если ВМ испытывает проблемы с производительностью, проверьте не использует ли она память с удаленной NUMA-ноды.
- Выводите ВМ из Swap как можно быстрее! Помимо всего прочего, если ВМ в Swap’е, по очевидным причинам страдает СХД.
На этом про оперативную память у меня все. Ниже статьи по теме для тех, кто хочет углубиться в детали. В следующей статье будет посвящена стораджу.
http://www.yellow-bricks.com/2013/06/14/how-does-mem-minfreepct-work-with-vsphere-5-0-and-up/
https://www.vladan.fr/vmware-transparent-page-sharing-tps-explained/
http://www.yellow-bricks.com/2016/06/02/memory-pages-swapped-can-unswap/
https://kb.vmware.com/s/article/1002586
https://www.vladan.fr/what-is-vmware-memory-ballooning/
https://kb.vmware.com/s/article/2080735
https://kb.vmware.com/s/article/2017642
https://labs.vmware.com/vmtj/vmware-esx-memory-resource-management-swap
https://blogs.vmware.com/vsphere/2013/10/understanding-vsphere-active-memory.html
https://www.vmware.com/support/developer/converter-sdk/conv51_apireference/memory_counters.html