
Все любят читать обзоры железа и софта, из которых можно понять, у какого продукта лучше получается решать поставленные задачи. Для этих целей часто используются синтетические тесты. В этот раз мы решили пройтись таким тестом по нашему сервису защиты веб-ресурсов: в него входит анти-DDoS, WAF (Web Application Firewall) и мониторинг событий ИБ.
Сервис отражает атаки, направленные на наших заказчиков. Критические ситуации в работе сервиса уже случались, но нам удавалось решить их в короткие сроки. Новый эксперимент стартовали в начале года, чтобы выяснить возможности защиты веба под нагрузкой и оценить риск прекращения работы клиентских сайтов. Спойлер: реальная жизнь оказалась интереснее.
Как проходил первый тест сервиса защиты веба
Для синтетической проверки используем такую методику:
- Атаки сетевого уровня, L3. Отправляем большое число запросов (Flood) на сетевом уровне (TCP, ICMP).
- Атаки прикладного уровня, L7. Отправляем большое число запросов (Flood) на прикладном уровне (например, HTTP(S)).
- Атаки методом Slow HTTP(S). Удерживаем множество одновременно открытых HTTP(S) соединений.
В комплексном сервисе трафик сначала отправляется на узлы очистки анти-DDoS (Qrator), потом проходит модули WAF и далее попадает на сайт. Так что генерируем трафик и смотрим результаты на графике в Qrator:
- красный – входящий трафик;
- синий – очищенный трафик;
- зеленый – обратный трафик, ответы веб-сервера.
Обнаружить атаку можем по всплескам входящего (красного) трафика.
Совмещаем время на графике с отчетом по тестированию:
Тип проверки/время |
|
|---|---|
Flood на сетевом уровне TCP, ICMP |
|
0:05 |
HTTPS-Flood, 10000 RPS, 5 мин |
0:30 |
HTTPS-Flood, 20000 RPS, 5 мин |
Flood на прикладном уровне HTTPS |
|
0:54 |
SSL-Flood, 10000 сессий, 5 мин |
1:03 |
SSL-Flood, 10000 сессий, 5 мин |
Slow HTTPS |
|
1:27 |
HTTPS-Slow, 10000 сессий, 5 мин |
1:40 |
HTTPS-Slow, 20000 сессий, 5 мин |
Понимаем, что пик первой атаки не продержался и минуты: анти-DDoS выявил и блокировал нападение за это время. Блокировка началась со среза половины атаки, и дальше все изменения в характере нападения никак не отразились на прошедшем трафике – до фронтенда дошел уже очищенный трафик. Повторили несколько раз – результат тот же.
Отлично, мы проверили наш сервис, ресурсы заказчика будут защищены! Или нет?
Что стало со вторым тестом в конце февраля
После 24 февраля стало понятно, насколько первая проверка была необходима и достаточна. Веб-приложения нескольких российских заказчиков подверглись целевым атакам “хактивистов”. Адреса их сайтов попали на специализированные ресурсы, где всем желающим предлагали стать участниками DDoS против российских компаний.
Часть атак шла со стороны ботов, часть атак использовала ресурсы обычных пользователей. Поэтому трафик не отличался от пользовательского, но его цель и некоторые параметры подключения совпадали с ботами. Серверы не справлялись с нагрузкой и переставали отвечать на запросы легитимных пользователей. Своих ресурсов для блокировки атак у компаний не было, многие обратились к нам.
На первый взгляд, ситуация похожа на первый тест: трафик идет на нескольких уровнях. Но есть нюансы:
- Объем трафика доходит до нескольких Гб. Если у заказчика вообще нет защиты от DDoS сетевого уровня, то сервер сразу захлебывается от такого количества и не может продвинуть запросы в приложение.
- Если же у заказчика cрабатывает защита от DDoS, то в приложение идут уже мегабайты трафика. Но, поскольку L7 более ресурсоемок и содержит больше тонких настроек, часто и этого объема достаточно для падения приложения.
Мы срочно заводили такие компании за анти-DDoS и WAF и мониторили, как сервис справляется с нагрузкой.
При этом заказчики сервиса защиты веба, которые уже были под защитой, не почувствовали атаки. На их примере мы смогли проанализировать характер нападения, подкрутить настройки WAF и использовать этот профиль как шаблон для других заказчиков.
Как отбивались атаки на сетевом уровне и уровне приложения
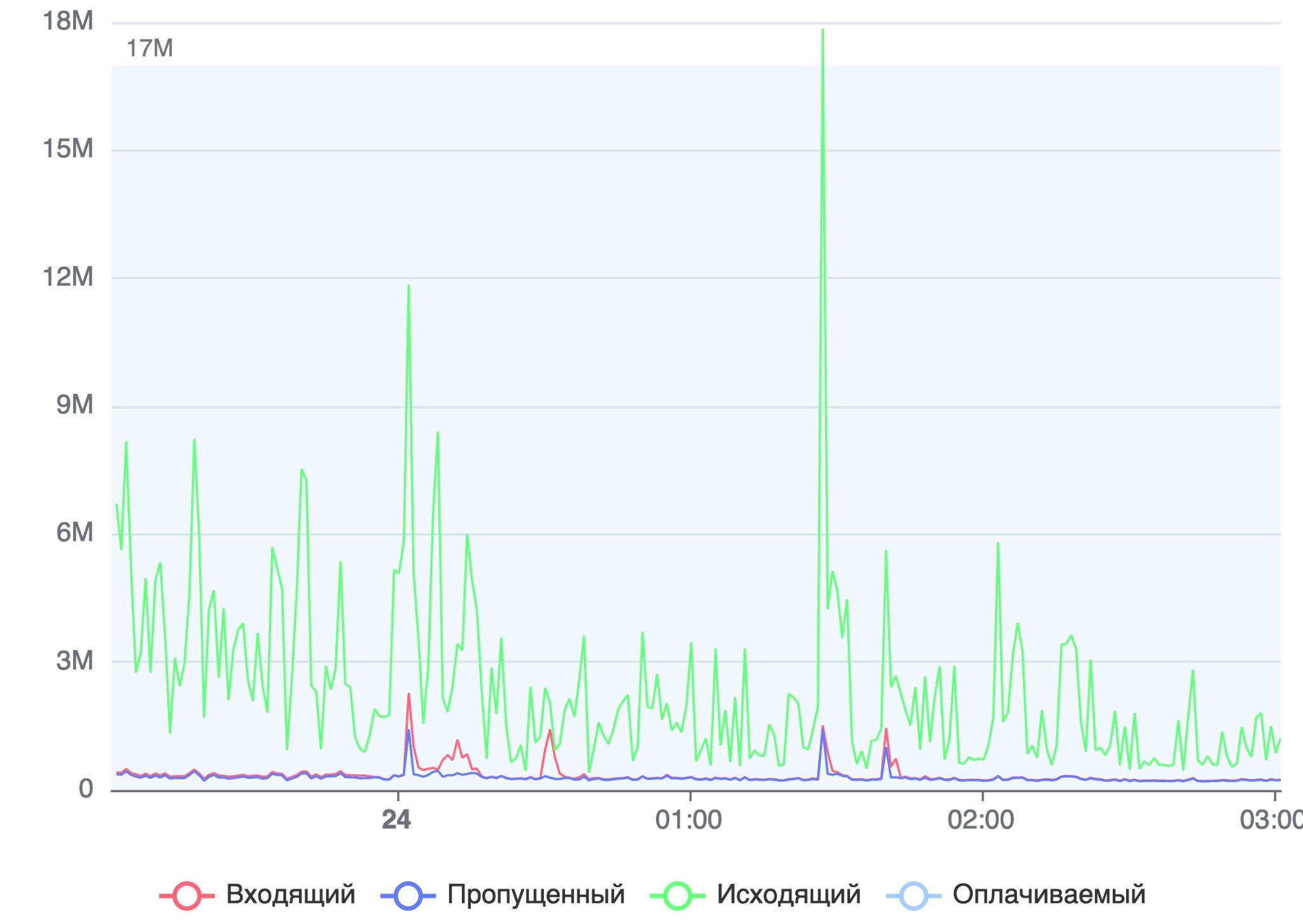
Возьмем одного из заказчиков комплексного сервиса, который подвергся атаке в марте. Вот что происходило с трафиком по отчету системы мониторинга на базе ELK:

Красное – отраженная атака. Остальное – легитимные подключения.
Из этого дашборда пошли глубже. Посмотрели журналы и убедились, что часть атаки срезал модуль Geo IP, немного потрудился IP Reputation, а с основной частью помогли заранее настроенные правила WAF.

Но стоит отметить, что мартовская атака была более мощной. Вот скрин из Qrator: в левой части графика видим ситуацию в феврале. А в правой – мартовский график, атака уже в гигабайтах:
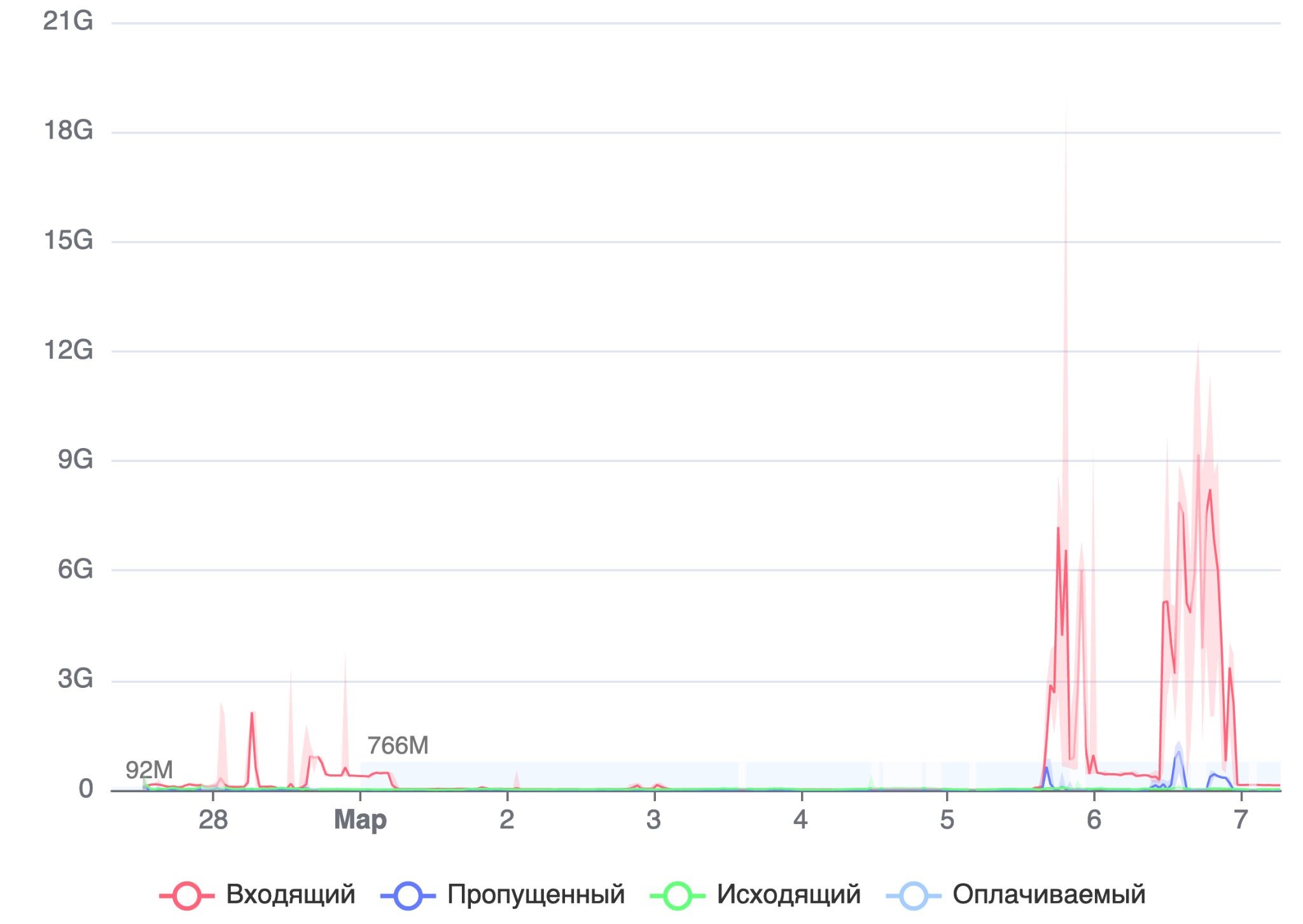
Мы предвидели риск усиления атак, так что продолжали готовиться к ним. Наибольшую трудность представляла “пользовательская” часть атаки: она не срезалась на анти-DDoS и при усилении могла уронить приложения.
Мы копили статистику по атакам и постоянно подкручивали параметры WAF. Например, выявляли и блокировали параметры запросов, непохожие на обычных пользователей:
- Частотные характеристики: количество запросов с нетипичными параметрами выше определенного порога.
- Тип клиента: пользователи обращаются не через браузер, а через специфическое ПО.
- Расположение источника запроса: мы продолжали пополнять “коллекцию” адресов, с которых идут атаки.
Параллельно с этим отлаживали схему заведения за WAF под атакой:
- Заказчикам было важно оказаться под защитой в течение пары часов: если атаковались популярные сайты, каждый час простоя грозил убытками. Поэтому сначала мы уделяли внимание защите на сетевом уровне и в течение 2-3 часов ставили сайт за сервис со среднестатистическим паттерном защиты. Анти-DDoS сразу отсекал гигабайты трафика. А на WAF шли блокировки для наиболее типичного поведения атакующих. Это также помогало серверам сразу вздохнуть спокойнее, пока мы копили статистику.
В чем отличие от стандартной схемы: в обычной ситуации мы не ставим защиты WAF сразу на блокировку, а согласуем все с заказчиком. Но при реальной атаке ложноположительные срабатывания не так страшны, как падение серверов. Поэтому предупреждали заказчика и сразу блокировали по шаблону.
- После этого появлялось больше времени для тюнинга тонких настроек на WAF. Например, можно искать для каждой компании подозрительные геолокации, где у заказчика точно нет клиентов, а трафик почему-то идет.
Здесь уже можно согласовывать блокировки с заказчиком, чтобы ничего не сломать.
- Для заказчиков в зоне риска создали рекомендации по подготовке к атаке:
- Проверить узкие места в инфраструктуре, например: где все держится на одном балансировщике, или для нескольких приложений на бэкенде стоит одна база.
- Поставить на мониторинг показатели доступности всех основных узлов инфраструктуры, чтобы сразу отследить точки отказа.
- Выяснить ответы на вопросы:
- кто управляет DNS-зоной;
- кто отвечает за SSL-сертификаты и закрытые ключи;
- c кем и как нужно согласовать передачу сертификатов и ключей, если решили встать за анти-DDoS;
- кто из специалистов отвечает за разные части веб-приложения.
Эта информация в будущем позволяла быстрее помочь клиенту под атакой.
Организационная часть порой оказывалась даже более важной: заводить сайт под атакой сложнее из-за отсутствия информации о норме поведения для приложения. Поэтому чем больше данных у заказчика было собрано на входе, тем быстрее мы подключали сервис. Смогли бы мы отладить эту схему на синтетическом тесте? Вряд ли.
***
Что показал синтетический тест WAF? Не всегда удается выяснить необходимую информацию при попытке симулировать атаку: ряд факторов мы просто не можем контролировать. Поэтому верить только синтетическим тестам не стоит, проверка в бою не менее важна.
В каком-то смысле мы даже любим наших дорогих злоумышленников: с интересом следим, как меняются паттерны атак, изучаем их утилиты и пытаемся перенять их поведение и фишки для имитации нападений. В конце концов, не только же opensource-утилитами все тестировать. Но об этом как-нибудь в следующий раз.