
В отличие от моих прошлых статей, сегодня мы поговорим о людях. Герои дня — служба эксплуатации, чьи интересы я представляю, и служба разработки.
Слаженная работа этих служб — залог успешного запуска и ровного «полёта» создаваемого сервиса. Но, как показывает мой (и не только) опыт, практически ни один проект не обходится без конфликтов и разногласий, жертвой которых становится ни в чем не повинный сервис.
В этой статье я постараюсь ответить на следующие вопросы:
- Как методы и процессы разработки отражаются на эксплуатации?
- Что движет каждой стороной конфликта?
- В чем первопричина разногласий?
Какие задачи стоят перед службами
Познакомимся с отделами поближе и начнем со службы эксплуатации (она же служба поддержки). Зачем нужен этот страшный зверь, какую задачу он выполняет и “на кого” работает?
Основная задача службы эксплуатации — это управление уровнем сервисов, то есть поддержание работы IT-системы в рамках SLA.
Эксплуатация должна обеспечивать постоянный доступ к сервису и его корректное функционирование в рамках соглашения с заказчиком — как правило, с бизнесом.
Вот из чего складывается решение этой задачи:
- Управление инцидентами: восстановление работоспособности бизнес-функции при аварии;
- Управление проблемами: устранение вероятных причин аварий и инцидентов,
- Управление конфигурациями: сбор информации и анализ параметров работы ПО и инфраструктуры;
- Управление изменениями: минимизация риска возникновения проблем и аварий при изменениях.
Роль службы разработки также понятна — первоначальное создание ИТ-сервиса и внедрение в него нового функционала по желанию заказчика.
Наверняка, у вас уже есть подозрения по поводу точек трения разработчиков и поддержки, ведь где возникают пересечения задач, там появляются конфликты.
Но не спешите с выводами. Извечные споры разработчиков и админов — это далеко не эпицентр «боёв».
Откуда растут разногласия
”Война” программистов и админов — это не противостояние человеческих интересов, это конфронтация служб.

Проблема заключена в приоритетах и мотивации этих самых служб. В самом общем виде это можно описать так:
- Команда разработки хочет использовать технологии первой свежести (профессиональное развитие, интерес) и выполнять работу как можно быстрее (внешняя мотивация).
- Эксплуатация заинтересована в как можно более стабильных технологиях (их проблемы известны и имеют общепринятые решения) и подробных разъяснениях, что им делать в случае возникновения проблем в разработанном ПО (внешняя мотивация на скорость устранения проблем).
При этом важно понимать, что не всегда только разработчики «пилят» новый функционал и не всегда исключительно админы поднимают упавшее.
- Админы активно участвуют в процессе разработки — в построении инфраструктуры, схем обеспечения отказоустойчивости и масштабируемости, в подготовке первоначальных конфигураций, а в идеале и в процессе подготовки требований к ПО. Всё это называется процессом разработки решения (не путайте с непосредственным написанием кода!).
- Программисты активно участвуют в эксплуатации. Они исправляют программные ошибки, выполняют системные оптимизации и технические доработки для соблюдения SLA системой, то есть решают задачи доступности конечного ИТ-сервиса.
Конфликт между программистами и админами растет из подмены понятий:
- разработка → написание кода;
- поддержка → администрирование прикладных сервисов.
Перекос структуры подчинения по профессиональному признаку (а не по функциональному) всегда приводит к конфликтам. Как правило, администраторы и программисты работают в совершенно разных командах, а иногда и отделах, и мотивируются как эксплуатация и разработка соответственно.
В результате программисты из отдела разработки, которых «заставляют» устранять старые баги или, не дай Бог, писать документацию, недовольны. Точно так же негодуют и админы из эксплуатации, которых просят по-быстрому подкинуть рояльчик поднять новый сервак для разработчиков или помочь им советом.
Каждая из сторон воспринимает это не в качестве совместного решения проблемы, а как отвлечение от собственных задач, которым и без того конца и края не видно.
Но нельзя забывать и про заказчика, ведь он, хоть и косвенно, также является участником конфликта. Как правило, ему нужно получить установленный и стабильно работающий сервис. “Голый” код, даже самый хороший, вне системы для заказчика совершенно бесполезен. У него в принципе другая картина мира:

У стандартного заказчика нет задачи что-то создать, написать или, прости, господи, внедрить. Заказчик хочет решить бизнес-проблему с помощью волшебной кнопки «Сделать всё хорошо», в то время как IT навязывает предлагает ему конкретное решение.
Давайте взглянем на все стороны конфликта:
| Разработка | Эксплуатация | Заказчик | |
|---|---|---|---|
| Задача | Наиболее полная и точная реализация требований заказчика. | Соблюдение uptime и, по возможности, адаптация к изменениям окружения. | Решение бизнес-проблемы. |
| KPI | Сроки выхода в релиз. | Uptime, время реакции, время устранения проблемы (SLA), параметры работы системы. | Годовой план, экономия бюджета, расширение рынка. |
| Мотивация | Сдать в срок, сделать что-то новое. | Быстро чинить, минимизировать количество аварий. | Реализовать свои идеи в развитии бизнес-процесса. |
| Понятие качества | Сделано то, что хотел заказчик. Использованы современные технологии. Технически проект выглядит красиво и удобен в использовании. | Всё работает стабильно, в том числе, не падает из-за действий пользователя. События отслеживаются, логика работы понятна, легко обслуживать и восстанавливать систему после сбоев. | Полнота, точность и эффективность решения его проблемы, удобство использования созданного инструмента и невозможность его утраты. |
Разумеется, это только самая общая часть функциональных и эксплуатационных требований.
Итак, мы выяснили, что в конфликте все-таки три участника: уже упомянутые разработка и эксплуатация, и заказчик. Причем именно заказчик во многом выступает «провокатором», разделяя ответственность между командами. Это само по себе неплохо, и, если бы не общепринятое разделение команд и обязанностей между ними, это был бы управляемый конфликт.
Но мы уже знаем, что обе службы не самодостаточны. Они разделены “служебной” баррикадой и при этом должны не только взаимодействовать между собой на поле передачи ответственности сообразно стадиям жизни продукта, но и активно участвовать в решении проблем друг друга.
Другой аспект влияния заказчика — его стратегия и методология развития бизнеса. В данном случае я говорю о непонимании, как выглядит процесс разработки конкретного IT-решения. Не обладая таким пониманием, заказчик часто требует сделать из кота кита, а потом, внезапно, приделать ему крылья. И всегда всё срочно. Иногда это оправдано ситуацией и новаторством идеи, иногда это следствие гонки за лидером рынка и спешное копирование. Причины могут быть самые разные, но итог один.
Беда в том, что подобная стратегия выливается в постоянные эксперименты и необходимость получить результат в минимальные сроки. Такой подход бросает нас в пучину непрерывной разработки вместо работы, нацеленной на конкретный результат. В принципе, последнюю проблему решают энтерпрайз-архитекторы, но этих ребят днем с огнем не сыщешь.
Процессы разработки
Наконец-то мы почти добрались до того, ради чего всё затевалось. Что имеет ключевое значение для службы эксплуатации?
- Прозрачность выполненных доработок. Для управления изменениями необходимо понимать, что, как и зачем было сделано.
- Документация по логике работы и обслуживанию. В идеале — в виде инструкций. Залог соблюдения SLA — не только надежность, но и четкое понимание, что и как делать, которое должно присутствовать у всех исполнителей. «Устные знания» здесь не подходят — очень часто в эксплуатации люди работают сменами, и просто невозможно всех собрать и все объяснить. Да и память в стрессовой ситуации (а авария — это всегда стресс) может подвести.
- Внятная процедура передачи в поддержку новой версии с тестированием ее эксплуатационных характеристик и корректности работы функционала. По-простому — регресс и нагрузочное тестирование. Простая работоспособность нового функционала волнует эксплуатацию в наименьшей степени: команда разработки сама починит неудачный релиз по гарантии. А вот привнесенную ошибку в старом функционале эксплуатация должна если не устранить самостоятельно, то хотя бы обработать, иногда и доказать вину разработки.
- Возможность передать свои требования к работе нового проекта. Именно разработка закладывает важнейшие эксплуатационные характеристики. К примеру, если ПО не умеет работать в кластере — эксплуатация не сможет самостоятельно сделать его действительно надежным.
Что такое служба эксплуатации и почему для кого-то вообще важно, как работает команда разработки, мы разобрались. Перейдем к самому интересному — разберем различные методологии разработки и их влияние на службу эксплуатации.
Начнем с классики: модели Waterfall.
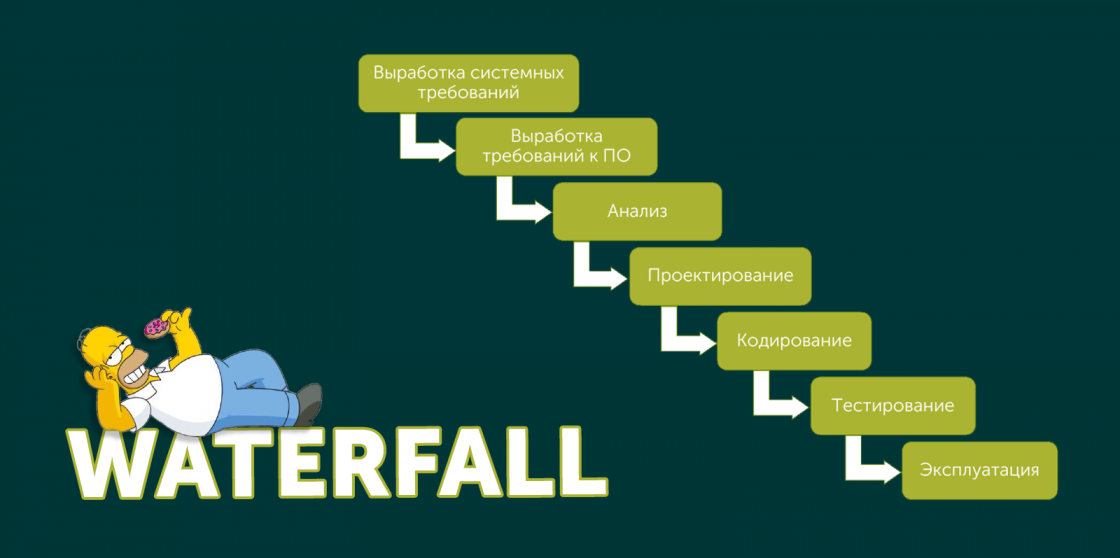
Waterfall ориентирован на доставку законченных и проработанных функциональностей. Релизная модель — циклическая. Цикл занимает от нескольких недель (крайне редко) до кварталов и полугодий. Практически всегда происходит последовательный сбор требований, их анализ, выработка архитектуры решения, оценка его длительности, планирование, полноценное регрессионное тестирование в конце.
Соблюдение интересов эксплуатации зависит от конкретной реализации. Так как нужные стадии обычно выделены, процесс предполагает учет всех требований и формальные процедуры передачи в эксплуатацию, в том числе и документацию.
Основные проблемы Waterfall для заказчика — это продолжительность итераций и долгая стабилизация после релиза. Иногда заказчик вынужден ждать по несколько месяцев, прежде чем в продуктиве появится функционал, на создание которого достаточно недели.
Если результат далек от ожидаемого, заказчику придется потерпеть до конца нового цикла, а то и двух. Регулярно на его месте оказывается и служба эксплуатации. А технический функционал чаще всего стоит последним в очереди.
Каждый большой релиз сопровождается ворохом ошибок, который устраняется в период стабилизации. Обычно он превращается в ад для всех сторон — разработка вынуждена заниматься эксплуатацией, эксплуатация принимает инциденты и всеми силами “впихивает” их разработке на гарантийное устранение, а заказчик, глядя на весь этот бардак и потерянные деньги, рвет на себе волосы.
Несмотря на всё это, с точки зрения эксплуатации, Waterfall — наиболее равномерный и предсказуемый методологический процесс, в который можно встроиться. В целом, ни продолжительность цикла, ни стабилизация эксплуатацию особенно не волнуют. Чем больше времени пройдет между релизами, тем дольше удастся спокойно поработать — а это всегда плюс. Кроме того, когда есть уверенность в том, что еще полгода ничего не поменяется, гораздо проще вписывать в процесс свои работы.
К сожалению, очень часто заказчики настроены против Waterfall и требуют ускорить разработку проекта. В угоду этому желанию рождаются более гибкие методологии.
Agile

Как вы поняли, Waterfall — это очень долго, формально и влечет за собой тонны документации, на которой все и всегда халтурят. А заказчик требует всего и сразу. Как ответ на эти проблемы программисты придумали Agile манифест:
- Люди и взаимодействие важнее процессов и инструментов.
- Работающий продукт важнее исчерпывающей документации.
- Сотрудничество с заказчиком важнее согласования условий контракта.
- Готовность к изменениям важнее следования первоначальному плану.
Трудно с этим поспорить. Конечно, люди важнее. Но о процессах тоже не стоит забывать. Именно процессы стандартизируют и регулируют взаимодействие. К тому же, только на людях далеко не уедешь. Как минимум, человеки любят болеть, отдыхать и иногда увольняться.
Это тоже верно. Но есть другой вопрос: а как хорошо и как долго будет работать продукт без документации? Вероятнее всего, не очень долго. А хорошо или нет — разобраться не получится ввиду отсутствия первоисточника. И дальше придется следовать полюбившейся многим тактике «не смог разобраться — перепиши с нуля». Но это всегда долго, дорого, и вообще не факт, что результат получится лучше.
И снова да, важнее. Но как без согласования условий контракта мы поймем, что и как нужно сделать? Как еще преодолевать взаимное недопонимание, кроме как общаться и договариваться посредством четко прописанного документа? Конечно, контракт — тоже не панацея, но он гораздо надёжнее, чем метод из девяностых:
— Вася, ты меня понимаешь?
— Ну, типа да, брат.
А вот это верно только в одном случае: если первоначальный план — полное бревно и то, что собирались построить, оказалось никому не нужно. Даёшь энтерпрайз-архитектора в каждые руки!
Результат слепого следования этому манифесту — в энтерпрайз-архитектора вынужден превратиться сам бизнес-заказчик (но чаще всего от такого он превращается в тыкву). Мало того, что это не свойственный ему “функционал”, так еще и в IT придется разобраться.
SCRUM

Scrum — это одна из первых попыток подогнать Waterfall под идеологию Agile манифеста. Основные черты скрама:
- Работа короткими спринтами. Состав спринта после его начала не редактируется;
- Планирование путем помещения отдельных User Story в журнал пожеланий спринта. На владельце проекта — выбор из «журнала проекта»;
- Интересы заказчика представляет владелец проекта (Product Owner);
- Команда разработки состоит из специалистов разных профилей: программисты, разработчики, архитекторы, аналитики. Команда отвечает за результат как единое целое;
- Документацию и переписку заменяем на ежедневные обсуждения проекта всей командой.
В теории, это достаточно здравый подход, и во многом он напоминает миниатюрную версию Waterfall. Проблемы начинают возникать на этапе реализации. К сожалению, SCRUM из-за более короткого цикла провоцирует разбивать целостную функцию на отдельные куски и доставку функции по частям еще на этапе планирования спринта. Я молчу о том, что по этой причине всё может пойти наперекосяк уже во время “забега”. Короткие спринты не оставляют времени на менеджерский запас и выкрутиться становится крайне сложно.
В результате постоянной переприоритезации фича в готовом виде может весьма нескоро попасть в продуктив. К тому же, на этапе написания UserStory крайне сложно оценивать влияние планируемого функционала на конечную систему, так как заранее неизвестно её состояние в тот момент, когда таки появится этот функционал.
Чем это грозит эксплуатации? Не всегда понятно, что должно работать, что не должно, а если заработает, то когда. Соответственно, происходит подмена тестирования системы на тестирование функции, так как нормальный регресс займет много времени. Это добавляет ошибок в продуктив и затягивает их решение.
Для нормальной работы эксплуатация должна:
- Участвовать в SCRUM-встречах;
- Постоянно быть в курсе рабочих ситуаций у разработки;
- Знать планы разработки и статусы по релизам.
В противном случае, успеть с приёмкой или сделать замечания будет невозможно. Конечно же, следовать всем этим пунктам у эксплуатации получается крайне редко, а если и получается, то это ведет к эскалации конфликта. Даже product-owner во время SCRUM-встречи может недальновидно проигнорировать интересы поддержки.
Kanban

Следующий шаг в эволюции методологий разработки — это Kanban. И без того короткие циклы SCRUM тоже показались бизнесу слишком долгими. Заказчика можно понять: всегда хочется первым получить самую крутую фишку. Да и менять планы неэффективно, получается многовато “накладных расходов”.
Так что, как говорят строители, проще “лепить по месту”.
Kanban представляет из себя IT-реализацию японской методологии бережливого производства. Но есть нюанс: в Toyota с помощью Kanban машины собирают из заранее спроектированных частей, между тем как разработка — это в первую очередь проектирование. В программировании части-функции просто копируются, их не надо постоянно “производить”.
Kanban обычно идет рука об руку с процессами CI/CD. Спринтов здесь уже нет, задачи доставляются непрерывно по мере готовности, существуют жесткие ограничения на размеры таких задач. Из-за этого сложный функционал в целостном виде не доставляется почти никогда, так как не укладывается в размер задачи.
В таких условиях документация на систему действительно устаревает раньше, чем пишется, и теряет всякий смысл, так как нельзя зафиксировать какое-то состояние производимой (именно производимой, а не разрабатываемой) системы, в котором она была бы верна.
Для эксплуатации это означает невозможность обеспечить SLA: документации нет, и никто не знает, как работает система и как она должна работать.
Предсказуемость и гарантия продолжительной работы является основой выполнения SLA.
Впрочем, при таком подходе и службы эксплуатации обычно нет, только команда разработки, периодически отвлекающаяся на ремонт и (иногда) на «технический долг». Но никто из-за этого не переживает, так как планы не срываются. Сложно сорвать то, чего нет.
Как это и закладывалось авторами оригинального процесса, Kanban идеален для операционной деятельности, в которой планирование заменено реакцией на раздражители. Например, так выглядит работа с инцидентами — что сломалось, то и починим. В большинстве случаев, по известной процедуре. Однако Kanban совершенно не подходит для разработки, так как слабо подразумевает конечный результат. Выбор этой методологии обречет вас на бесконечный процесс — “мы строили, строили и до сих пор строим”. Не надо так!
DevOps
Конечно, DevOps — это не методология разработки как таковая, но я не могу не вставить свои 5 копеек и не рассказать про самую распространенную попытку решить конфликт эксплуатации и разработки.
В теории, DevOps — это набор практик, нацеленных на активное взаимодействие специалистов по разработке со специалистами по информационно-технологическому обслуживанию и взаимную интеграцию их рабочих процессов друг в друга.
Базируется DevOps на идее тесной взаимозависимости разработки и эксплуатации программного обеспечения и нацелен на то, чтобы помогать организациям быстрее создавать и обновлять программные продукты и услуги. Снова про быстрое создание и обновление. Но для эксплуатации этих проблем вообще не существует. В итоге DevOps становится средством сделать команду разработки независимой от службы эксплуатации с помощью достраивания необходимого разработке звена. Очевидно, что само по себе это решение однобоко и решает проблему только для одной из сторон — разработки. Часто это лишь усугубляет конфликт, давая возможность разработке полностью игнорировать службу эксплуатации.
На практике я чаще всего встречаю две реализации:
- Команда админов эксплуатации сохраняется и занимается продуктивом.
В команде разработки появляются админы-автоматизаторы, решающие проблемы разработчиков вместо команды эксплуатации. Думаю, очевидно, что в итоге их решения, на скорую руку примененные в тестовых средах, в продуктив пускать не хочется, и конфликт только возрастает.
- То же самое, но команда эксплуатации упраздняется в духе принципа “нет человека — нет проблемы”.
Задачи управления доступностью сервиса уходят на второй план. Мотивированных на их решение людей вообще не остаётся. Периодически появляется команда DevOps-инженеров, но это ничего не меняет, так как приоритет их руководства — сроки выхода в релиз. Все прочие задачи можно задвинуть, пока никто не видит.
Если даже вернуться к исходной идее, что DevOps — это, скорее, про тестирование, и он должен гарантировать оперативный перенос гарантированно качественных изменений, то снова окажется, что исключать из процесса или заменять эксплуатацию нельзя. Фокус самой идеи именно в обеспечении качества процесса изменений и гарантии качества этих изменений. Заметьте, нигде не говорится про соблюдение SLA и управление доступностью. Да и высокое качество изменений (компонент) вообще не гарантирует высокую эффективность работы системы в целом.
Все предусмотреть и всё проверить невозможно — тестирование не гарантирует отсутствие аварий. Оборудование может износиться, система может выйти из строя в ходе эксплуатации в неожиданных условиях. Наконец, есть человеческий фактор.
Поэтому даже с командой DevOps без процесса эксплуатации не обойтись, и, как ни крути, документация понадобится. Когда что-то сломается, придется разбираться, как оно вообще работало.
Вместо вывода
Так что же делать и как быть?
Бизнесу: разрабатывать внятную стратегию развития своего продукта и управлять конъюнктурой рынка, а не спешно реагировать на изменения.
Разработке: не превращать заказчика в энтерпрайз-архитектора. Построение инженерных или ИТ-систем — не его профиль, он специалист в какой-то локальной области бизнеса.
Всем вместе: попытки избавиться от службы эксплуатации вполне могут оказаться успешными, но вряд ли вы сможете отказаться от самого процесса эксплуатации, доступность должна оставаться под контролем. Либо этим будут управлять выделенные профессионалы, либо это будет дополнительной нагрузкой для разработчиков, решать вам.
DevOps — отличная и полезная штука для повышения качества, но по описанным выше причинам также не позволит ничего гарантировать и не заменит полноценную эксплуатационную службу. Этот подход не решит конфликт разработки, эксплуатации и бизнеса, но поможет обеспечить процесс непрерывной приёмки и снизит общее напряжение.
Наверняка все вы так или иначе участвовали в описанных выше ситуациях и процессах. Поделитесь своим опытом в комментариях!