
Привет! Меня зовут Александр Соловьев, я программист компании DataLine.
Хочу поделиться опытом внедрения модных нынче нейронных сетей в нашей компании.
Все началось с того, что мы решили строить свой Service Desk. Зачем и почему именно свой, можно почитать у Алексея Волкова тут.
Я же расскажу о недавнем новшестве в системе: нейросеть в помощь диспетчеру первой линии поддержки.
Уточнение задачи
Головная боль любого диспетчера службы поддержки – нужно быстро принять решение, кому назначить входящий запрос клиента. Вот какие бывают запросы:
Добрый день.
Я правильно понимаю: чтобы расшарить календарь на определенного пользователя, нужно на ПК пользователя, который хочет поделиться календарем, открыть доступ к своему календарю и вписать почту пользователя, которому он хочет дать доступ?
По регламенту диспетчер должен отреагировать в течение двух минут: зарегистрировать заявку, определить срочность и назначить ответственное подразделение. При этом диспетчер выбирает из 44 подразделений компании.
Инструкции диспетчеров описывают решение для большинства типичных запросов. Например, к простым заявкам относится предоставление доступа в дата-центр. Но вот заявки на обслуживание включают множество задач: установку ПО, анализ ситуации или сетевой активности, выяснение деталей по тарификации решений, проверку всевозможных доступов. Иногда из запроса сложно понять, кому из ответственных отправить вопрос:
Hi Team,
The sites were down again for few minutes from 2020-07-15 14:59:53 to 2020-07-15 15:12:50 (UTC time zone), now they are working fine. Could you please check and let us know why the sites are fluctuating many times.
Thanks
Бывали ситуации, когда заявка уходила не тому подразделению. Запрос брали в работу и затем переназначали на других исполнителей или отправляли обратно диспетчеру. Это увеличивало скорость решения. Время на решение запросов прописано в соглашении с клиентом (SLA), и мы несем ответственность за соблюдение сроков.
Внутри системы мы решили создать помощника для диспетчеров. Основная цель была – добавить подсказки, которые помогают сотруднику принимать решение по заявке быстрее.
При этом мы точно не планировали заменять диспетчеров на чат-ботов, так как хотим, чтобы клиенты по-прежнему общались с живым человеком.
Больше всего не хотелось поддаться новомодной тенденции и посадить чат-бота на первой линии поддержки. Если вы хоть раз пытались написать в такую техподдержку (уже кто только этим ни грешит), вы понимаете, о чем я.
Во-первых, он тебя понимает очень плохо и по нетипичным заявкам не отвечает совсем, во-вторых, до живого человека очень сложно достучаться.
Сначала я думал отделаться дешево и сердито и попробовал подход с ключевыми словами. Мы составили словарь ключевиков в ручном режиме, но этого оказалось недостаточно. Решение справлялось только с простыми заявками, с которыми как раз и не было проблем.
За время работы нашего Service Desk’a у нас накопилась солидная история заявок, на основе которой можно распознавать похожие входящие запросы и назначать их сразу на правильных исполнителей. Вооружившись гуглом и некоторым количеством времени, я решил углубиться в изучение вариантов решения.
Изучение теории
Оказалось, что моя задача – классическая задача классификации. На входе алгоритм получает первичный текст заявки, на выходе относит его к одному из заранее известных классов – то есть, подразделений компании.
Вариантов решений нашлось великое множество.
Это и "нейронная сеть", и "наивный байесовский классификатор", "метод ближайших соседей", "логистическая регрессия", "дерево решений", "бустинг" и еще много-много всяких вариантов.
Пробовать все методики не хватило бы никакого времени. Поэтому я остановился на нейронных сетях (давно хотел попробовать поработать с ними). Как оказалось впоследствии, этот выбор вполне себя оправдал.
Итак, я начал погружение в тему нейросетей отсюда. Изучил алгоритмы обучения нейросетей: с учителем (supervised learning), без учителя (unsupervised learning), с частичным привлечением учителя (semi-supervised learning) или "с подкреплением" (reinforcement learning).
В рамках моей задачи подошел метод обучения с учителем. Данных для обучения хоть отбавляй: over 100k решенных заявок.
Выбор реализации
Для реализации выбрал библиотеку Encog Machine Learning Framework. К ней идет доступная и понятная документация с примерами. К тому же реализация под Java, что мне близко.
Кратко механика работы выглядит так:
- Предварительно настраивается каркас нейросети: несколько слоев нейронов, соединенных связями-синапсами.
- В память загружается набор данных для обучения с заранее известным результатом.
- Данные для обучения прогоняются через каркас нейросети. В результате у каждого синапса в зависимости от данных выстраиваются "веса". По этим "весам" нейросеть принимает то или иное решение.
- После прогоняем нейросеть через тестовую выборку и анализируем "ошибку" сети: насколько результат, выдаваемый нейросетью, соответствует известному результату из набора данных.
- Пункты 3 и 4 повторяются до получения минимально допустимой ошибки. При этом важно, чтобы на каждой следующей итерации ошибка уменьшалась. Если этого не происходит, значит какие-то из параметров были выбраны некорректно.
Я попробовал различные примеры фреймворка, пришло понимание, что с цифрами на входе библиотека справляется на ура. Так, хорошо работал пример с определением класса ирисов по размеру чаши и лепестков (Ирисы Фишера).
Но у меня-то текст. Значит, буквы нужно как-то превратить в цифры. Так я перешел к первому подготовительному этапу – "векторизации".
Первый вариант векторизации: по буквам
Самый простой способ превратить текст в цифры - это взять алфавит на первом слое нейросети. Получаются 33 буквы-нейрона: АБВГДЕЁЖЗИКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ.
Каждой присваивается цифра: наличие буквы в слове принимаем за единицу, а отсутствие считаем нулем.
Тогда слово "привет" в такой кодировке будет иметь вектор:
| А | Б | В | Г | Д | Е | Ё | Ж | З | И | Й | К | Л | М | Н | О | П | Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Такой вектор уже можно отдать нейросети для обучения. Ведь это число
001001000100000011010000000000000 = 1216454656Углубившись в теорию, я понял, что анализировать буквы нет особого смысла. Они не несут никакой смысловой нагрузки. Например, буква "А" будет в каждом тексте заявки. Считайте, что этот нейрон всегда включен и на результат никакого влияния не окажет. Как и все остальные гласные. Да и в тексте заявки будет большинство букв алфавита. Такой вариант не подходит.
Второй вариант векторизации: по словарю
А если взять не буквы, а слова? Скажем, толковый словарь Даля. И считать за 1 уже наличие слова в тексте, а отсутствие – за 0.
Но тут я уперся в количество слов. Вектор получится очень большой. Нейронка с 200k нейронов на входе будет считаться целую вечность и захочет много-много памяти и процессорного времени. Надо делать свой словарь. К тому же в текстах есть ИТ-специфика, которую Владимир Иванович Даль не знал.
Я снова обратился к теории. Для сокращения словаря при обработке текстов пользуются механизмами N-грамм – последовательности из N элементов.
Идея в том, чтобы входной текст разбить на некоторые отрезки, составить из них словарь и в качестве 1 или 0 скормить нейросети наличие или отсутствие фразы в исходном тексте. То есть вместо буквы, как в случае с алфавитом, за 0 или 1 будет принята не просто буква, а целая фраза.
Самыми популярными являются униграммы, биграммы и триграммы. На примере фразы "Добро пожаловать в ДатаЛайн" расскажу о каждой из методик.
- Униграмма – текст разбивается на слова: "добро", "пожаловать", "в", "ДатаЛайн".
- Биграмма – разбиваем на пары слов: "добро пожаловать", "пожаловать в", "в ДатаЛайн".
- Триграмма – аналогично по 3 слова: "добро пожаловать в", "пожаловать в ДатаЛайн".
- N-грамма – ну вы поняли. Сколько N, столько и слов подряд.
- Также иногда используют символьные N-граммы. Текст делится не на слова, а на последовательность букв. Например 4-символьная N-грамма выглядела бы так: "добр","о по", "жало", "вать" и т. д. Но тут получится очень большой словарь.
Я решил ограничится униграммой. Но не просто униграммой – слов все равно получалось многовато.
На помощь пришел алгоритм "Стеммер Портера", который использовался для унификации слов еще в 1980 году.
Суть алгоритма: убрать из слова суффиксы и окончания, оставляя только базовую смысловую часть. Например, слова "важную", "важны", "важные", "важный", "важным", "важных" приводим к базе "важн". То есть вместо 6 слов в словаре будет одно. А это значительное сокращение.
Дополнительно я убрал из словаря все цифры, знаки пунктуации, предлоги и редко встречающиеся слова, дабы не создавать "шума". В итоге на 100k текстов получился словарь в 3k слов. С этим уже можно работать.
Обучение нейросети
Итак у меня уже есть:
- Словарь из 3k слов.
- Векторизованное представление словаря.
- Размеры входного и выходного слоев нейросети.
По теории на первом слое (входном) предоставляется словарь, а финальный слой (выходной) – количество классов-решений. У меня их 44 – по количеству подразделений компании.
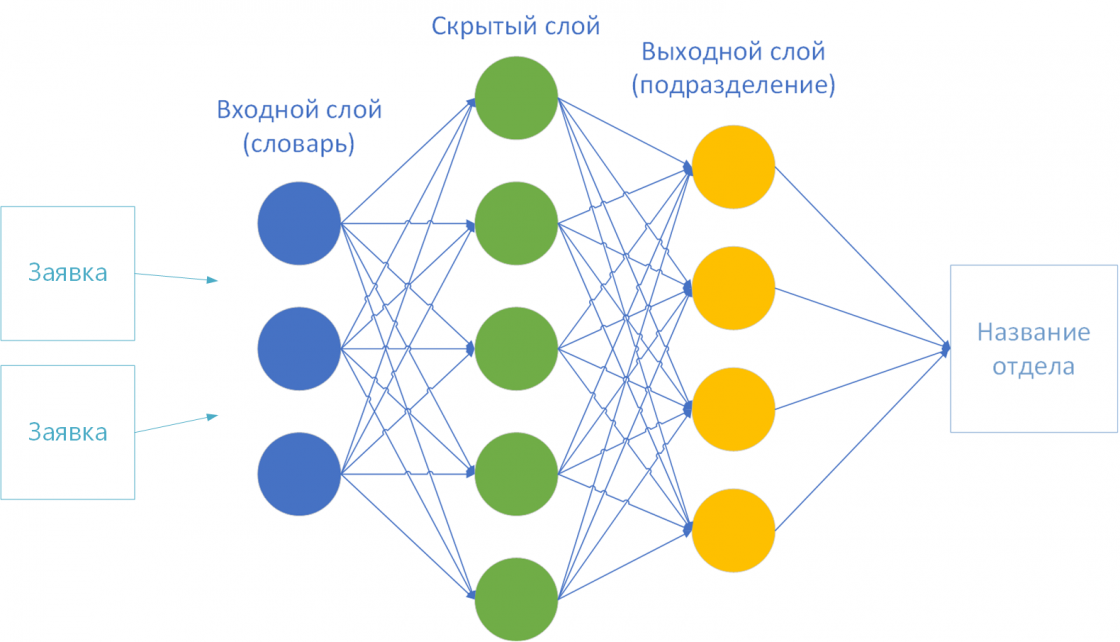
Для обучения нейросети осталось выбрать совсем немного:
- Метод обучения.
- Функцию активации.
- Количество скрытых слоев.
Как подбирал параметры. Параметры всегда подбираются опытным путем для каждой конкретной задачи. Это самый долгий и утомительный процесс, так как требует множества экспериментов.
Итак, я взял эталонную выборку заявок в 11k и делал расчет нейросети с различными параметрами:
- На 10k я обучал нейронную сеть.
- На 1k проверял уже обученную сеть.
То есть на 10k мы строим словарь и обучаемся. А затем показываем обученной нейросети 1k неизвестных текстов. В итоге получается процент ошибки: отношение угаданных подразделений к общему числу текстов.
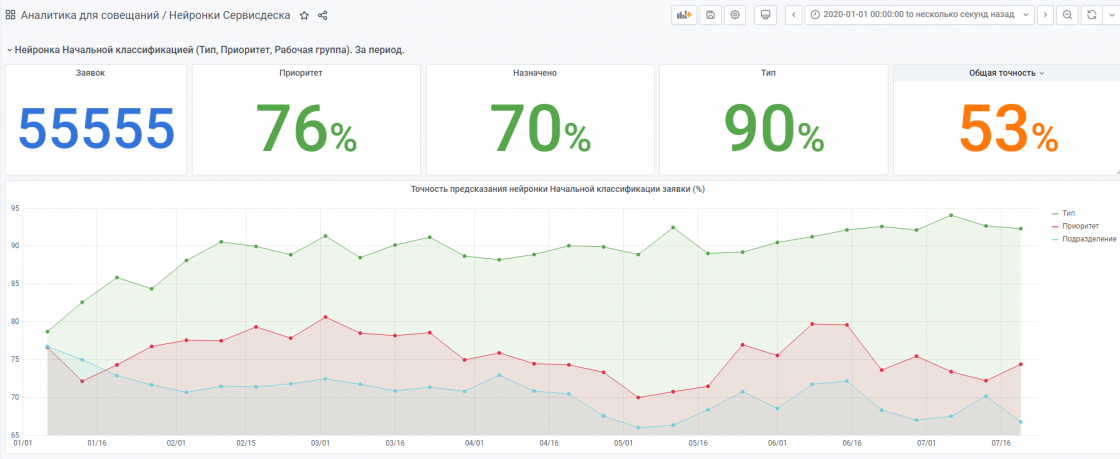
В итоге я добился точности на неизвестных данных около 70%.
Опытным путем выяснил, что обучение может продолжаться бесконечно, если выбраны неверные параметры. Пару раз нейронка уходила в бесконечный цикл расчета и знатно подвешивала рабочую машинку на ночь. Чтобы не допустить этого, для себя я принял ограничение в 100 итераций или пока ошибка сети не перестанет уменьшаться.
Вот какие параметры получились в итоге:
Метод обучения. Encog предлагает выбрать из нескольких вариантов: Backpropagation, ManhattanPropagation, QuickPropagation, ResilientPropagation, ScaledConjugateGradient.
Это разные способы определения весов у синапсов. Какие-то из методов работают быстрее, какие-то точнее, подробнее лучше почитать в документации. Мне подошел Resilient Propagation.
Функция активации. Она нужна для определения значения нейрона на выходе в зависимости от результата взвешенной суммы входов и порогового значения.
Выбирал из 16 вариантов. Проверить все функции у меня не хватило времени. Поэтому рассматривал самые популярные: сигмоид и гиперболический тангенс в различных реализациях. В итоге остановился на ActivationSigmoid.
Количество скрытых слоев. По теории, чем больше скрытых слоев, тем дольше и сложнее расчет. Начал с одного слоя: расчет был быстрый, но результат неточный. Я остановился на двух скрытых слоях. С тремя слоями считалось заметно дольше, а результат не сильно отличался от двухслойного.
На этом эксперименты закончил. Можно готовить инструмент к продуктиву.
В продакшен!
Дальше дело техники.
- Прикрутил Spark, чтобы можно было общаться с нейронкой по REST.
- Научил сохранять результаты расчета в файл. Не каждый же раз пересчитывать при перезапуске сервиса.
- Добавил возможность вычитывать актуальные данные для обучения напрямую из Service Desk. Ранее тренировался на csv-файлах.
- Добавил возможность пересчета нейросети, чтобы прикрутить пересчет к планировщику.
- Собрал все в толстый jar.
- Попросил у коллег сервер помощнее разрабской машины.
- Задеплоил и зашедулил пересчет раз в неделю.
- Прикрутил кнопку в нужное место Service Desk и написал коллегам, как этим чудом пользоваться.
- Сделал сбор статистики по тому, что выбирает нейронка и что выбрал человек (статистика ниже).
Вот так выглядит тестовая заявка

Но стоит нажать "волшебную зеленую кнопку", и происходит магия: поля карточки заполняются. Диспетчеру остается убедиться, что система подсказывает верно, и сохранить заявку.
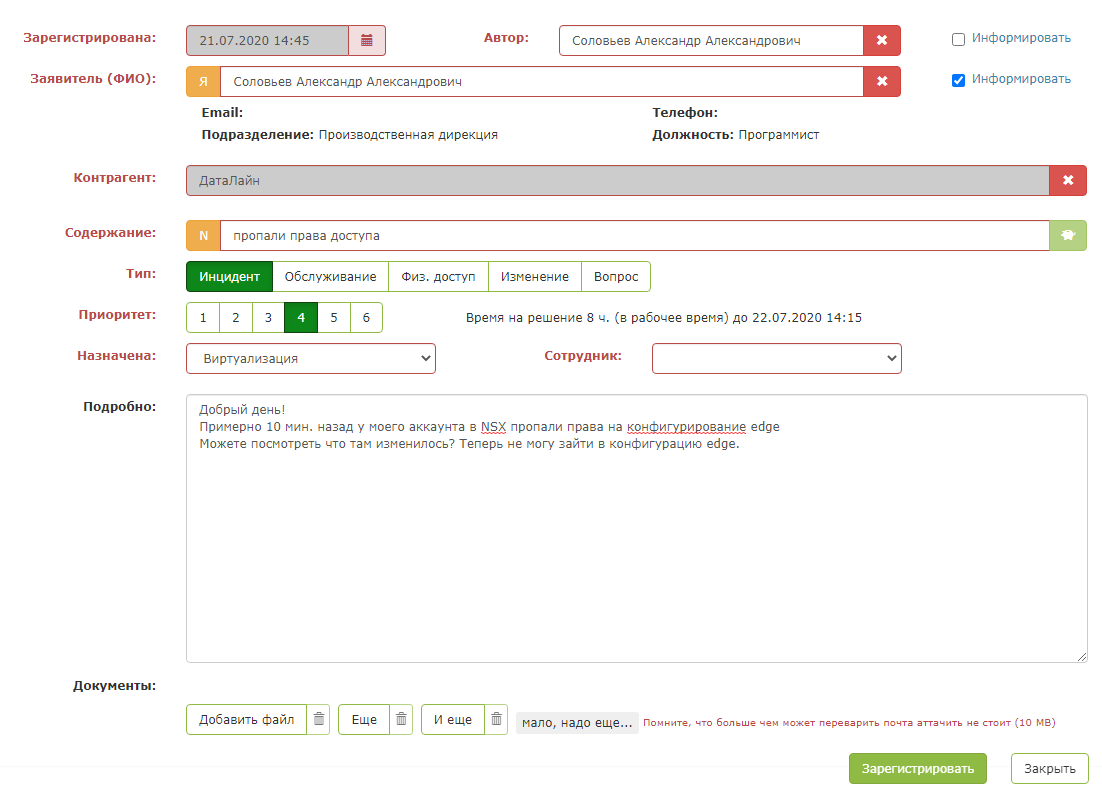
Получился такой интеллектуальный помощник для диспетчера.
Для примера статистика с начала года.
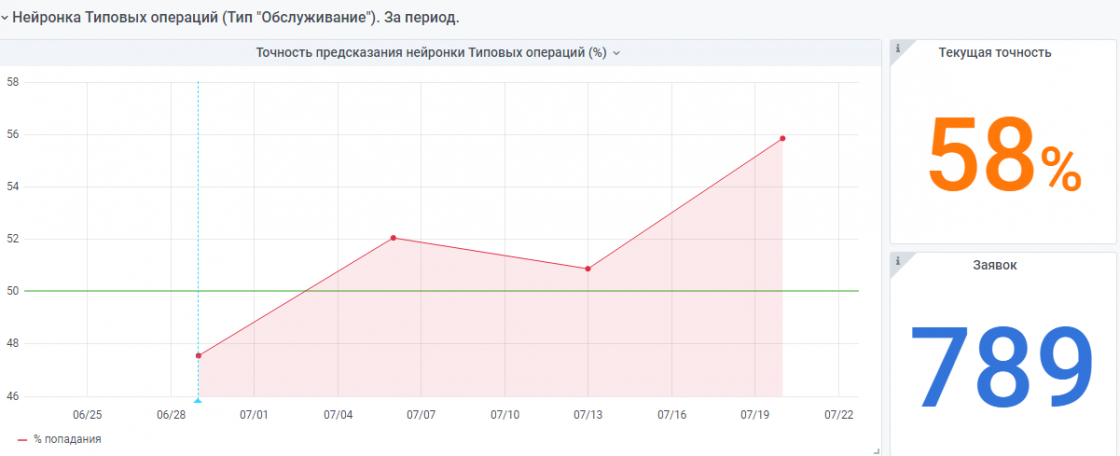
Есть еще "совсем молодая" нейросеть, сделанная по тому же принципу. Но там данных еще мало, она пока набирается опыта.
Буду рад, если мой опыт поможет кому-нибудь в создании своей нейросети.
Если есть вопросы, с удовольствием отвечу.
