
После новогодних праздников мы перезапустили катастрофоустойчивое облако на базе двух площадок. Сегодня расскажем, как это устроено, и покажем, что происходит с клиентскими виртуальными машинами при отказе отдельных элементов кластера и падении целой площадки (спойлер – с ними все хорошо).
Что внутри
Под капотом у кластера серверы Cisco UCS с гипервизором VMware ESXi, две СХД INFINIDAT InfiniBox F2240, сетевое оборудование Cisco Nexus, а также SAN-свичи Brocade. Кластер разнесен на две площадки – OST и NORD, т. е. в каждом дата-центре идентичный набор оборудования. Собственно, это и делает его катастрофоустойчивым.
В рамках одной площадки основные элементы тоже продублированы (хосты, SAN-свитчи, сетевка).
Две площадки соединены выделенными оптоволоконными трассами, тоже зарезервированными.
Пару слов про СХД. Первый вариант катастрофоустойчивого облака мы строили на NetApp. Здесь выбрали INFINIDAT, и вот почему:
- Опция Active-Active репликации. Она позволяет виртуальной машине оставаться в работоспособном состоянии даже при полном отказе одной из СХД. Про репликацию расскажу подробнее дальше.
- Три дисковых контроллера для повышения отказоустойчивости системы. Обычно их два.
- Готовое решение. К нам приехала уже собранная стойка, которую только нужно подключить к сети и настроить.
- Внимательная техподдержка. Инженеры INFINIDAT постоянно анализируют логи и события СХД, устанавливают новые версии в прошивке, помогают с настройкой.
Вот немного фоточек с unpacking’а:


Как работает
Облако уже отказоустойчиво внутри себя. Оно защищает клиента от единичных аппаратных и программных отказов. Катастрофоустойчивое же поможет защититься от массовых сбоев в пределах одной площадки: например, отказ СХД (или кластера SDS, что случается нередко :) ), массовые ошибки в сети хранения и прочее. Ну и самое главное: такое облако спасает, когда становится недоступной целая площадка из-за пожара, блэкаута, рейдерского захвата, высадки инопланетян.
Во всех этих случаях клиентские виртуальные машины продолжают работать, и вот почему.
Схема кластера устроена так, что любой ESXi-хост с клиентскими виртуальными машинами может обращаться к любой из двух СХД. Если СХД на площадке OST выйдет из строя, то виртуальные машины продолжат работать: хосты, на которых они работают, будут обращаться за данными к СХД на NORD.
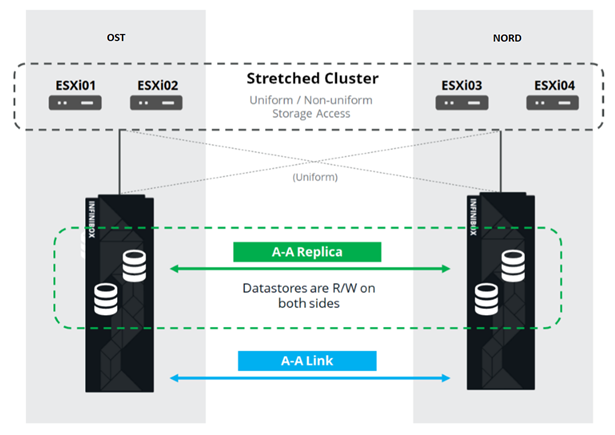
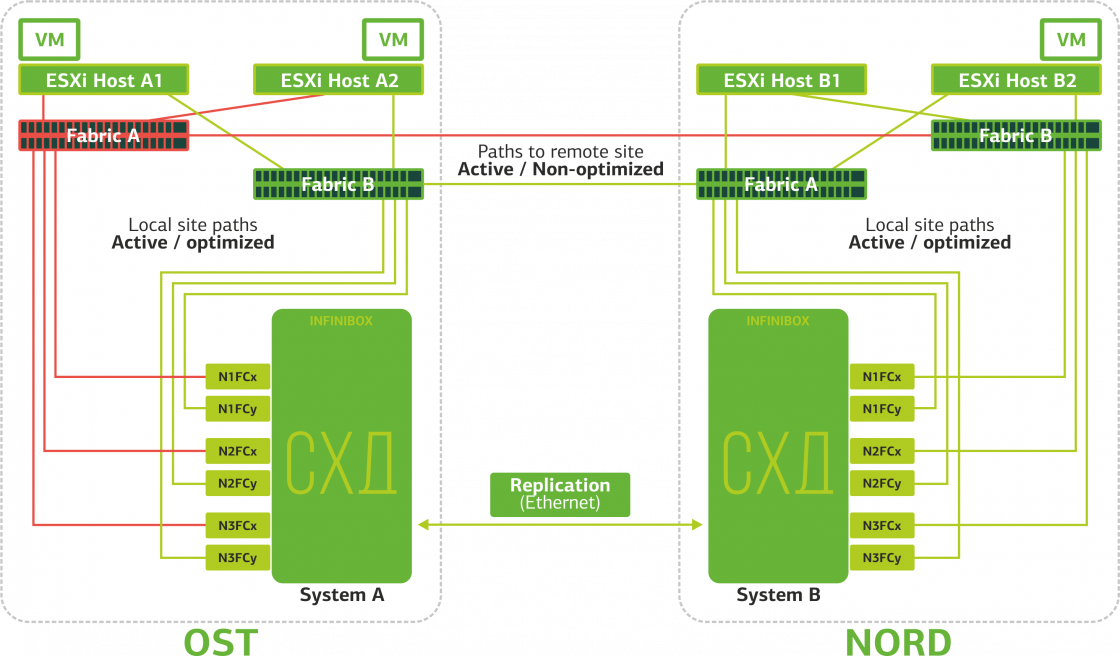
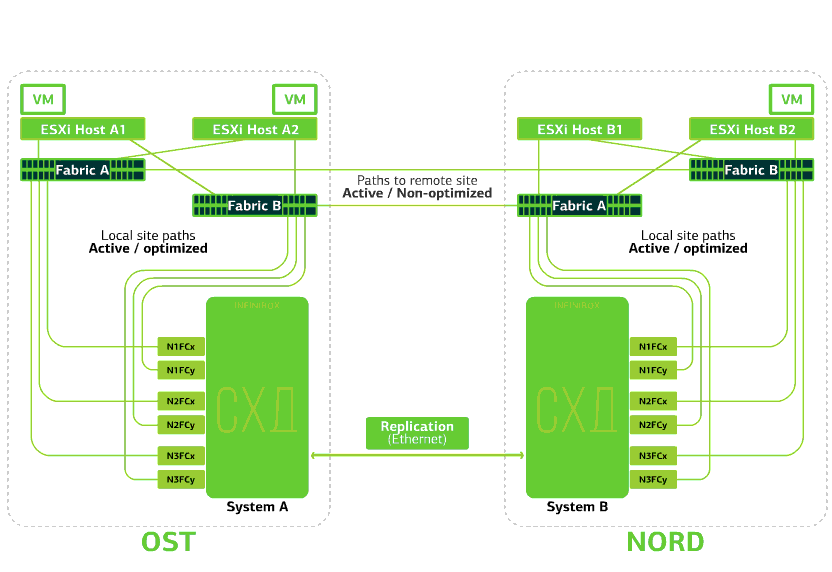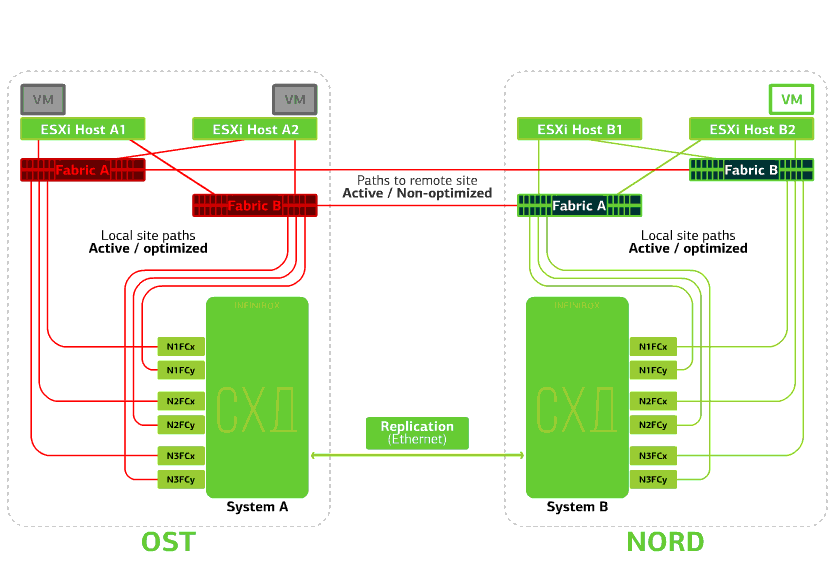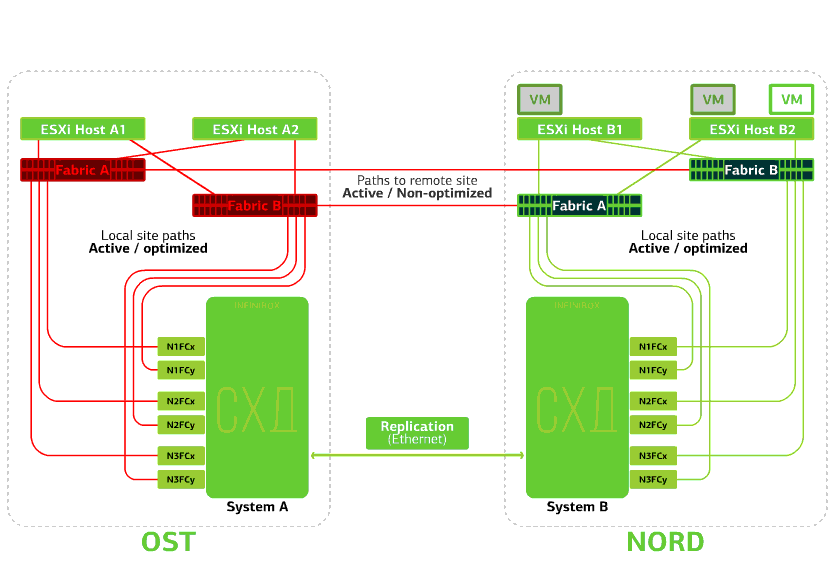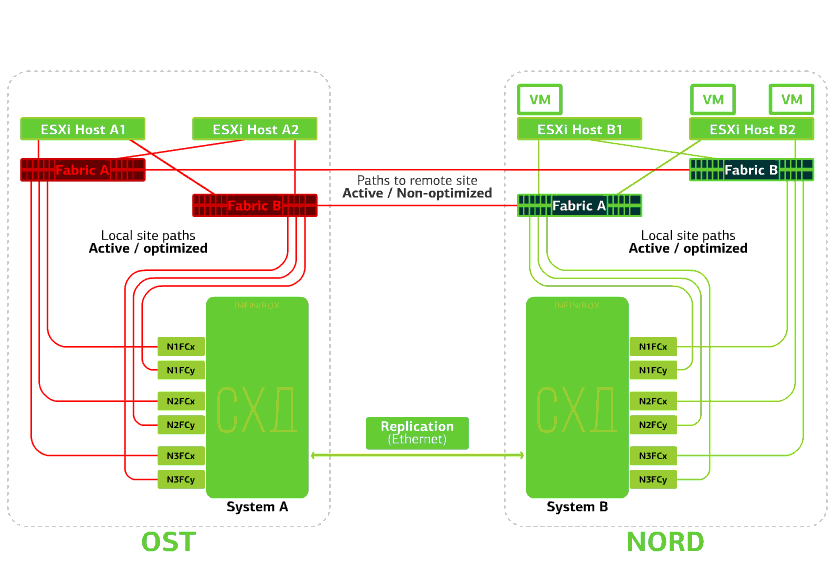
Вот так выглядит схема подключения в кластере
Это возможно благодаря тому, что между SAN-фабриками двух площадок настроен Inter-Switch Link: SAN-свитч Fabric A OST соединен с SAN-свитчем Fabric A NORD, аналогично и для SAN-свитчей Fabric B.
Ну и чтобы все эти хитросплетения SAN-фабрик имели смысл, между двумя СХД настроена Active-Active репликация: информация практически одновременно записывается на локальную и удаленную СХД, RPO=0. Получается, что на одной СХД хранится оригинал данных, на другой – их реплика. Данные реплицируются на уровне томов СХД, а уже на них хранятся данные ВМ (ее диски, конфигурационный файл, swap-файл и пр.).
ESXi-хост видит основной том и его реплику как одно дисковое устройство (Storage Device). От ESXi-хоста к каждому дисковому устройству идет 24 пути: 12 путей связывают его с локальной СХД (оптимальные пути), а остальные 12 – с удаленной (неоптимальные пути). В штатной ситуации ESXi обращается к данным на локальной СХД, используя оптимальные пути. При выходе из строя этой СХД ESXi теряет оптимальные пути и переключается на неоптимальные. Вот как это выглядит на схеме.
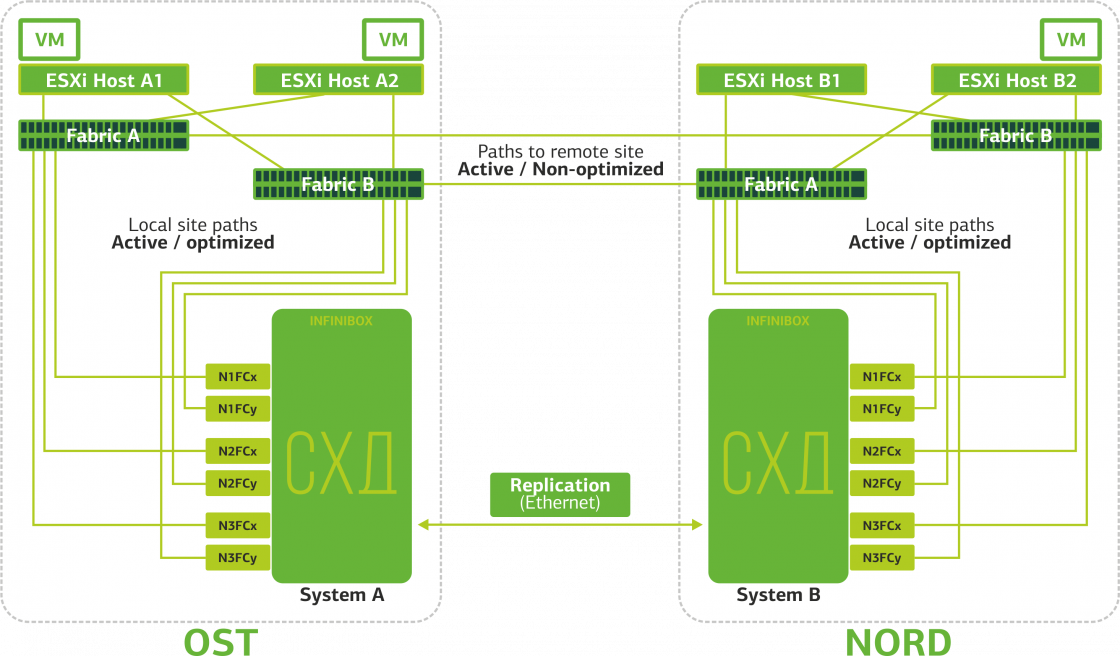
Схема катастрофоустойчивого кластера
Все клиентские сети заведены на обе площадки через общую сетевую фабрику. На каждой площадке работает Provider Edge (PE), на котором и терминируются сети клиента. PE объединены в общий кластер. При отказе PE на одной площадке весь трафик перенаправляется на вторую площадку. Благодаря этому виртуальные машины с площадки, оставшейся без PE, остаются доступными по сети для клиента.
Давайте теперь посмотрим, что будет происходить с виртуальными машинами клиента при различных отказах. Начнем с самых лайтовых вариантов и закончим самым серьезным – отказом всей площадки. В примерах основной площадкой будет OST, а резервной, с репликами данных, – NORD.
Что происходит с виртуальной машиной клиента, если...
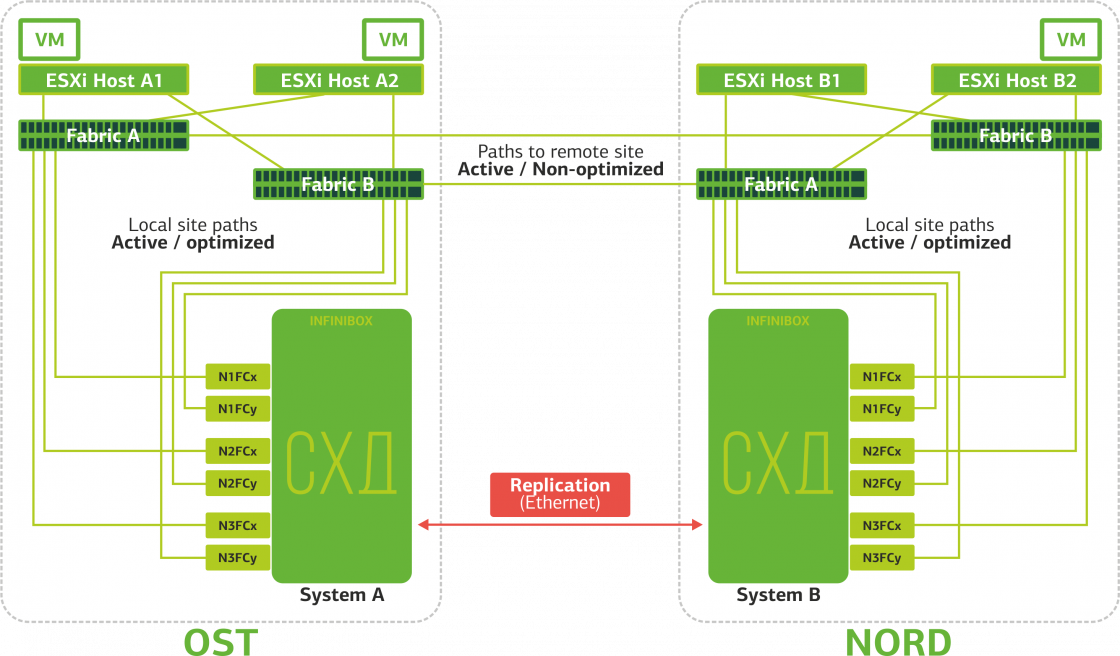
Отказывает Replication Link. Репликация между СХД двух площадок прекращается.
ESXi будут работать только с локальными дисковыми устройствами (по оптимальным путям).
Виртуальные машины продолжают работать.
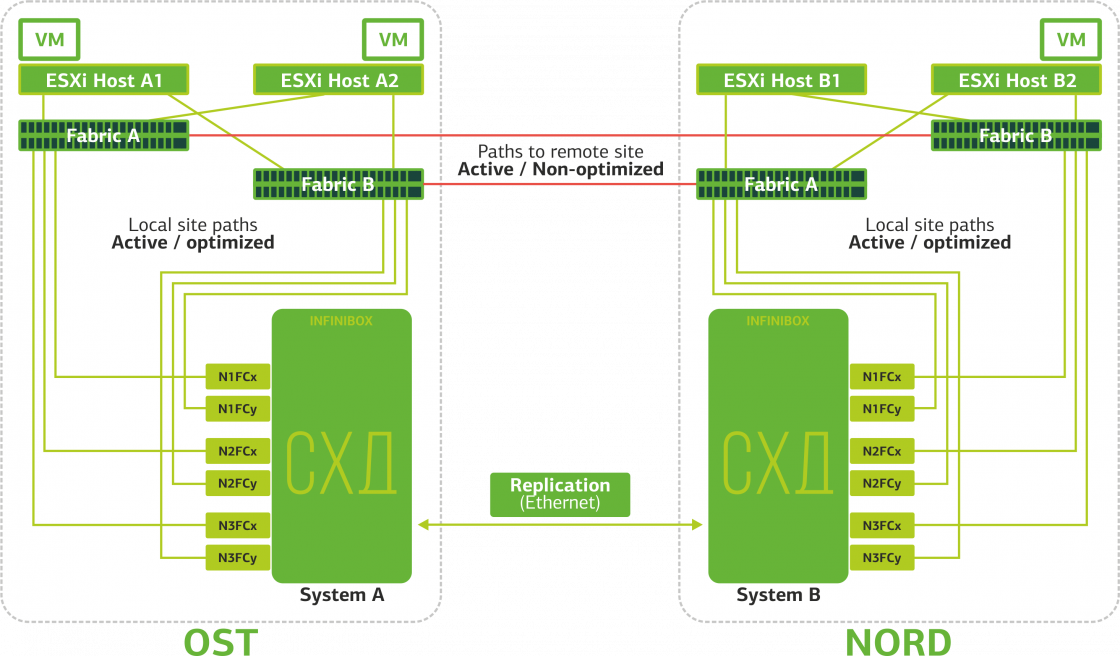
Происходит разрыв ISL (Inter-Switch Link). Случай маловероятный. Разве что какой-нибудь бешеный экскаватор перекопает сразу несколько оптических трасс, которые проходят независимыми маршрутами и заведены на площадки через разные вводы. Но все-таки. В этом случае ESXi-хосты теряют половину путей и могут обращаться только к своим локальным СХД. Реплики собираются, но хосты не смогут к ним обращаться.
Виртуальные машины работают штатно.
Отказывает SAN-свитч на одной из площадок. ESXi-хосты теряют часть путей к СХД. В этом случае хосты на площадке, где отказал свитч, будут работать только через один свой HBA.
Виртуальные машины при этом продолжают работать штатно.
Отказывают все SAN-свитчи на одной из площадок. Допустим, такая беда случилась на площадке OST. В этом случае ESXi-хосты на этой площадке потеряют все пути к своим дисковым устройствам. В дело вступает стандартный механизм VMware vSphere HA: он перезапустит все виртуальные машины площадки OST в NORD`е максимум через 140 секунд.
Виртуальные машины, работающие на хостах площадки NORD, работают штатно.
Отказывает ESXi-хост на одной площадке. Тут снова отрабатывает механизм vSphere HA: виртуальные машины со сбойного хоста перезапускаются на других хостах – на той же или же удаленной площадке. Время перезапуска виртуальной машины – до 1 минуты.
Если отказывают все ESXi-хосты площадки OST, тут уже без вариантов: ВМ перезапускаются на другой. Время перезапуска то же.
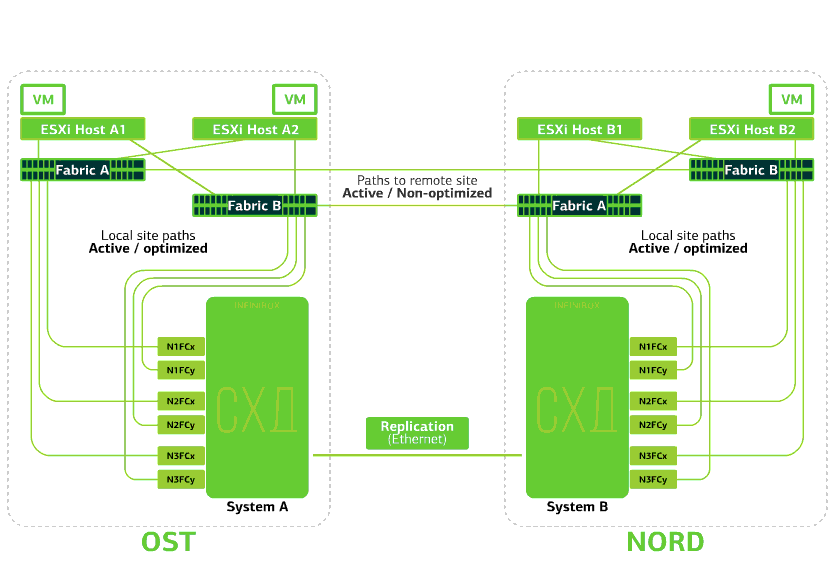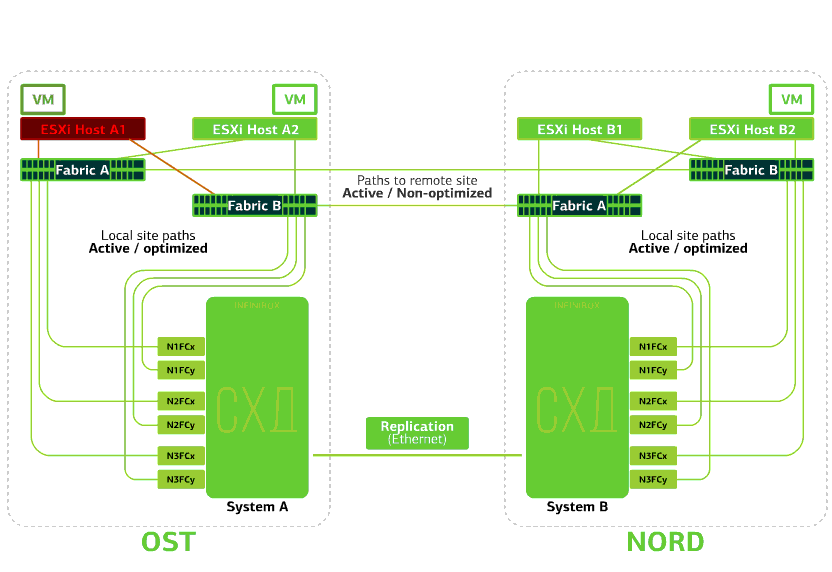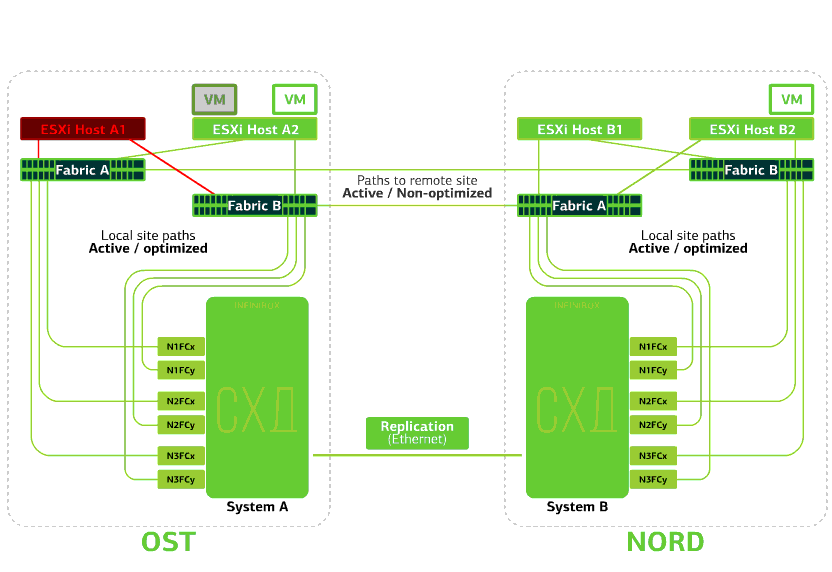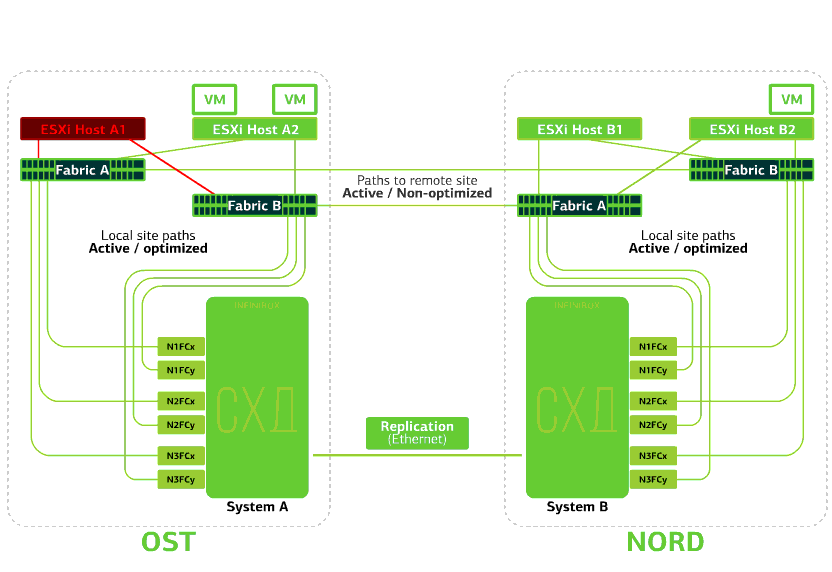
Отказывает СХД на одной площадке. Допустим, отказала СХД на площадке OST. Тогда ESXi-хосты площадки OST переключаются на работу с репликами СХД в NORD’e. После возвращения сбойной СХД в строй произойдет принудительная репликация, ESXi-хосты OST снова начнут обращаться к локальной СХД.
Виртуальные машины все это время работают штатно.
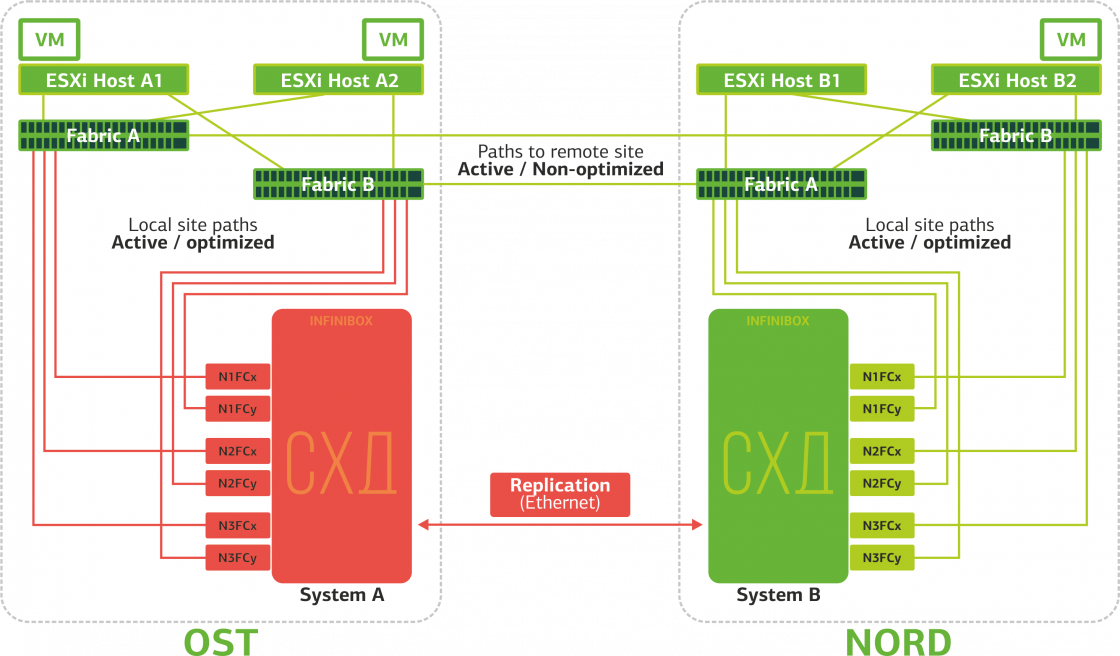
Отказывает одна из площадок. В этом случае все виртуальные машины будут перезапускаться на резервной площадке через механизм vSphere HA. Время перезапуска ВМ – 140 секунд. При этом все сетевые настройки виртуальной машины сохранятся, и она остается доступной для клиента по сети.
Чтобы перезапуск машин на резервной площадке прошел без проблем, каждая площадка заполнена только наполовину. Вторая половина – резерв на случай переезда всех виртуальных машин со второй, пострадавшей, площадки.

Вот от таких отказов защищает катастрофоустойчивое облако на базе двух дата-центров. Удовольствие это недешевое, так как, в дополнение к основным ресурсам, нужен резерв на второй площадке. Поэтому размещают в таком облаке бизнес-критичные сервисы, длительный простой которых несет большие финансовые и репутационные убытки, или если к информационной системе предъявляются требования по катастрофоустойчивости от регуляторов или внутренних регламентов компании.
Источники:
https://www.infinidat.com/sites/default/files/resource-pdfs/DS-INFBOX-190331-US_0.pdf
https://support.infinidat.com/hc/en-us/articles/207057109-InfiniBox-best-practices-guides