
В прошлом году мы активно взялись за быстродействие больших тяжелых баз данных в нашем облаке. На первый взгляд казалось, что у нас только 2 варианта: недорогие СХД с медленными дисками или очень дорогие СХД – с быстрыми.
Мы же хотели ускорить работу высоконагруженных баз данных Microsoft SQL и при этом предложить клиентам выгодную стоимость услуги. В результате тестов мы собрали решение “Кластер для нагруженных баз данных Microsoft SQL в облаке”. Сегодня заглянем внутрь и добавим чуть больше технических вводных и конкретных цифр.
Пост не претендует на deep dive и не раскрывает всех технических нюансов, а лишь демонстрирует результаты нашего тестирования. Я покажу, на каком железе, софте и конфигурации сети мы проводили тесты быстродействия БД, каким способом тестировали и какие результаты получили.
Условия задачи: на чем проверяли быстродействие БД
Как выбирали железо под кластер. На старте мы искали серверы с такими характеристиками:
- Имеют форм-фактор 1U. Какое-то время у нас были громоздкие четырехсокетные платформы с форм-фактором 2U, но так у нас было меньше возможностей “размазать” кластер по залам и повысить отказоустойчивость. Плюс в случае 1U уменьшается еще и домен отказа: меньше виртуальных машин перезагружается при падении хоста.
- Поддерживают установку бэкплейна на 10 отсеков с дисками формата U.2. В этом случае можно поставить много модных сейчас быстрых дисков NVMе. А чем больше у нас дисков, тем больше места для данных.
- Поддерживают Intel Optane DC Persistent Memory модули.
- Находятся в Hardware compatibility list (HCL) вендора Microsoft – так мы будем уверены в поддерживаемости конфигураций вендором.
- Ну и цена должна нас устраивать.
В результате мы остановили свой выбор на бренде Supermicro и модели 1029U-TN10RT:

Как мы и хотели, это сервер форм-фактора 1U, на котором можно разместить 2 процессора Intel Xeon Scalable.
Вот полная спецификация:
- Шасси – Ultra 1U SYS-1029U-TN10RT.
- CPU – 2 x Intel Xeon Gold 6246 (3.3GHz, 12C).
- Storage – 10 x Intel DC P4510 1TB NVMe SSD, 1DWPD.
- DRAM – 12 x 64GB DDR4-2666.
- Persistent Memory – 2 x 128GB DDR4-2666 Intel Optane DC PMMs.
- Network – 2 x 25GbE Mellanox ConnectX-4 Lx.
Практически вся передняя часть занята отсеками 2,5 дюйма для накопителей NVMe: как раз те самые 10 отсеков для дисков формата U.2.


Как организовали отказоустойчивость на уровне софта. На программном уровне работу платформы обеспечивают Windows Server 2019 и технология Storage Spaces Direct. Она позволяет объединить локальные диски серверов в подобие сетевого RAID – избыточного массива независимых дисков.
Сначала мы провели тест на двухузловом кластере и в итоге перешли к более надежной трехузловой конфигурации. Узлы кластера серверов разнесены по трем машинным залам. В качестве уровня избыточности томов используется 3-way Mirroring, так что данные каждой виртуальной машины хранятся в 3 копиях.
Дефолтный домен отказа – StorageRack. В перспективе это дает нам гибкость в масштабировании кластера с гарантией, что данные не будут размещены в рамках одной стойки. Выбрали такой уровень избыточности хранения, чтобы повысить доступность сервиса.
Как разбирались с задержками сети. Мы старались минимизировать задержки случайных операций записи и повысить производительность сети и хоста. Для этого мы уменьшали нагрузку на процессор и повышали пропускную способность. В результате решили использовать RDMA – удаленный прямой доступ к памяти. Выбрали сетевые карты Mellanox ConnectX-4 Lx c поддержкой RoCEv2 (RDMA over Converged Ethernet).
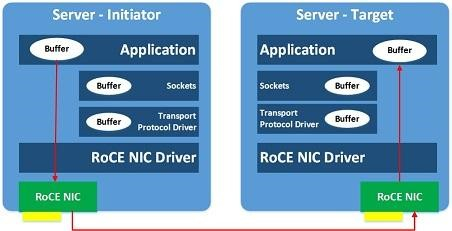
Благодаря RoCE мы разгружаем транспорт и процессор. Картинку взял у Mellanox
Решение: как и какие цифры получили
Производительность измеряли двумя независимыми инструментами. В качестве рекомендуемого использовали фреймворк VMFleet от Microsoft, а для чистоты эксперимента измеряли еще и при помощи FIO.
Первый тест. Для тестирования мы смоделировали среднестатистическую нагрузку для “тяжелых” баз данных. Развернули около 150 виртуальных машин c “толстыми” дисками по 40 GB, по 50 виртуальных машин на хост. Переподписка – 4:1, порог утилизации CPU – не более 60%. Количество томов – 3, объемом по 3 TB каждый.
На выходе мы получили такие данные.
CPU Oversubscription 4:1
| Metrics | 100% Random Read | 90% Random Read / 10% Random Write | 70% Random Read / 30% Random Write |
|---|---|---|---|
| IOPS per Volume | 475000 | 275000 | 169000 |
| Latency per Volume | 0,2 ms | 0,2 ms / 0,4 ms | 0,2 ms / 0,4 ms |
| BW (MB/s) per Volume | 7750 | 4500 | 2750 |
| IOPS per VM | 9500 | 5500 | 3380 |
| BW (MB/s) per VM | 155 | 90 | 55 |
| IOPS per GB | 237 | 137 | 84 |
| Metrics | 100% Random Read | 90% Random Read / 10% Random Write | 70% Random Read / 30% Random Write |
|---|---|---|---|
| IOPS per Volume | 509000 | 282000 | 190000 |
| Latency per Volume | 0,12 ms | 0,12 ms / 0,33 ms | 0,13 ms / 0,36 ms |
| BW (MB/s) per Volume | 2000 | 1150 | 780 |
| IOPS per VM | 10180 | 5640 | 3800 |
| BW (MB/s) per VM | 40 | 23 | 15 |
| IOPS per GB | 254 | 112 | 76 |
| Metrics | 100% Sequential Read |
|---|---|
| BW (MB/s) per Volume | 19000 |
| BW (MB/s) per VM | 380 |
Второй тест. Нам хотелось узнать максимум, на что способны эти хосты, так что решили нагрузить их по полной. Переподписку уменьшили до 2:1 (по 25 ВМ на хост), а порог загрузки CPU убрали. Паттерн теста был такой: 100% рандомное чтение блоком 4К с 4 тредами и глубиной 16 каждая. Вот что мы получили на выходе.

Видим, что задержки Read Lat довольно низкие
Сравнили результаты с FIO и с удивлением обнаружили, что данные практически одинаковы.
В результате для сервиса DBaaS Microsoft SQL мы смогли без сверхдорогих СХД значительно улучшить производительность. Для базы данных до 4 ТБ можем гарантировать до 200 000 IOPS с задержками менее 1 мс при 100% чтении блоком 4k.
Сейчас мы планируем цикл вебинаров по внутреннему устройству и принципам работы гиперконвергентных решений на базе Windows Server 2019 и технологии Storage Spaces Direct. Так что буду рад вашим вопросам!
