
Всем привет, на связи Алексей Приставко, директор по веб-проектам DataLine.
Ежегодно в последних числах ноября проходит Черная пятница, самая масштабная акция в мире e-commerce. Это пора рекордных скидок, магазины открываются чуть ли не в полночь, а сайты, участвующие в акции, падают, не выдерживая резко возросшего потока трафика.
На носу уже сентябрь, пора заканчивать эксперименты и готовиться к Черной пятнице — ведь времени уже в обрез.
Статья будет полезна IT-менеджерам, разработчикам и администраторам небольших интернет-магазинов, которые еще не готовили сайты к серьезному повышению нагрузки.
Кроме того, это часть «домашнего задания» для всех, кто 16 августа придет на мой одноименный семинар в Москве. Семинар будет необычный — большую часть времени я буду отвечать на вопросы и дискутировать с вами.
Под катом обстоятельно поговорим о том, как подготовить ваш сайт к Черной пятнице.
Чем грозит Черная пятница
Как я написал выше, Черная пятница — это день, который доставляет немало хлопот всем, кто занят в обслуживании e-commerce сайтов.
Чтобы это прочувствовать, рассмотрите график ниже. Он отражает рост числа запросов на сайте во время Черной пятницы.

По сравнению с нормальными дневными пиками, когда никаких акций не проводится, в Черную пятницу трафик растет на 100-200%, и это не предел.
Если у крупного сайта и без того много собственного трафика, то скромный интернет-магазин в период акции запросто получит столько же посетителей и захлебнется. Немного перефразируя старый анекдот: «бизнес сделал все магазины разными, а online Чёрная пятница всех уравняла».
Заработанное в Черную пятницу «кормит» продавца весь следующий год. Бизнес крайне заинтересован в привлечении максимального числа новых клиентов, которые будут возвращаться на сайт, чтобы покупать снова и снова. Но для этого их первый опыт общения с сайтом должен пройти гладко, а обеспечить это — задача IT-специалистов.
Чем больше клиентов одновременно находится на сайте, тем выше требования к его стабильности и скорости отклика. Наверняка вы замечали, что сайт магазина, на который вы переходили с лендинга blackfridaysales, работал крайне медленно или не работал вовсе. Сомневаюсь, что вы остались ждать загрузки, а не ушли через несколько секунд.
О том, как защитить покупателей от негативного опыта, а сайт – от падений из-за перегрузки, мы поговорим ниже. Впрочем, дальнейшие советы справедливы для любого предполагаемого пика нагрузки.
В целом, можно выделить два этапа подготовки сайта к повышенному трафику: технический и организационный. В этой статье мы обсудим технический этап, а организационные тонкости я подробно опишу во второй части, которая выйдет через неделю.
Техническая подготовка сайта

Небольшой дисклеймер: не ждите, что найдете здесь подробные указания, что, где и как надо подкрутить, чтобы пришло «счастье для всех, даром, и никто не ушел обиженный». Во-первых, сайты и проекты у всех разные. Во-вторых, конкретных технических советов по конкретному ПО более, чем достаточно. В том числе и на Хабре. В первую очередь я хочу донести до читателей фундаментальные принципы работы с веб-проектами и показать отправные точки, познакомить с основными техниками и платформонезависимыми нюансами.
Начнем с аксиомы: пользователь не любит ждать, поэтому крайне важно работать с таймингами и скоростью отклика. В Черную пятницу запросов к сайту станет намного больше, чем обычно, и вы можете столкнуться не только с падением конверсий из-за длительной загрузки, но и с превышением HTTP тайм-аутов (сайт не отвечает).
Чаще всего под нагрузкой сайты падают не из-за физических поломок, а из-за того, что время ответа стало превышать тайм-ауты вследствие перегрузки на каком-то узле. Это похоже на автомобильную пробку, и вам на время придется взять управление в свои руки: расширять (масштабировать) оборудование, регулировать, отсекать и настраивать (тайм-ауты), оптимизировать загруженность транспортных средств (пакеты и запросы), работать с исключениями.
Так как в контексте сайта производительность имеет два аспекта — скорость отклика и количество одновременно обрабатываемых запросов, будем улучшать эти параметры.
Чаще всего бизнес представляет скорость отклика как скорость сайта по Google Analytics, а количество одновременных запросов — как количество одновременно находящихся на сайте пользователей.
В технической работе этими параметрами оперировать не совсем удобно. Далее я предложу более подходящую для расчетов метрику.
Оптимизируем скорость отклика

При оптимизации скорости отклика нам интересны два показателя: скорость ответа сервера и время загрузки страницы.
Время загрузки (Page Load Time) складывается из следующих звеньев:
- Время генерации страницы сервером;
- Время передачи страницы от сервера к клиенту;
- Время обработки страницы в браузере клиента.
Когда все работает в штатном режиме, решающее значение для Page Load Time имеют не время генерации страницы сервером и время доставки страницы по сети, а качество фронт-энда и скорость работы сайта в браузере. Так как последнее целиком происходит на стороне пользователя, появления здесь тормозов в Черную пятницу можно не бояться. Однако проблемы могут возникнуть из-за перегрузок на вашем интернет-канале или на отдаче внешнего компонента (партнёрские счетчики, онлайн-чаты, плагины CRM и прочее).
Как с этим бороться? Вот несколько рабочих советов:
- Проверьте нагрузку интернет-канала. Посчитайте предполагаемый рост. Если появились сомнения, расширьте канал. Некоторые провайдеры, помимо дорогостоящего расширения на постоянной основе, могут предложить вам временное расширение на период пика (значительно дешевле) или вовсе позволят ненадолго превышать максимальную скорость.
- Используете CDN? Свяжитесь с техподдержкой и предупредите о плановом росте трафика. Они тоже готовятся ко всеобщему пику, и ваш прогноз придется очень кстати. Если CDN пообещает, что все будет хорошо, но, несмотря ни на что, «ляжет», наличие переписки поможет выставить требования о компенсации.
- Заранее проработайте сценарий временного отключения внешних компонентов в случае возникновения проблем. Согласуйте сценарий с бизнесом. Не лишним будет пообщаться с техподдержкой используемых сервисов, всё равно как-то иначе повлиять на них обычно невозможно.
- На многих сайтах статика отдается с помощью сервера приложения. Под высокой нагрузкой количество запросов к статике многократно возрастает, и они начинают конкурировать за ресурсы с самим приложением. Обязательно настройте отдачу статики напрямую с Nginx. Во-первых, с этим он справится намного лучше, а во-вторых, потокам ваших Apache, Tomcat или Jetty найдется куда более полезная работа.
Улучшаем скорость ответа

Сама по себе оптимизация скорости ответа относится к общему улучшению показателей сайта. Теоретически, она помогает уменьшить объем работы, совершаемой приложением, и за счет этого улучшает масштабирование — ведь если каждый запрос становится «дешевле», можно обработать больше запросов теми же ресурсами.
Но на практике оптимизация скорости ответа требует большого объема самостоятельной работы. Оптимизировать все сразу невозможно, а вот поломать что-то в процессе — запросто.
Совет: мыслите системно. Допустим, производительность кода возросла, и приложение стало делать больше одновременных запросов к базе данных. Но вот незадача: производительность БД не позволяет обрабатывать такое количество запросов, и сайту в целом стало только хуже, а драгоценное время до начала акции было потрачено.
Так что лучше сосредоточьтесь на масштабировании и масштабируемости, а общую оптимизацию выполняйте отдельно от подготовки к Черной пятнице, чтобы не напортачить из-за жестких дедлайнов. Помните, сейчас наша задача — добиться, чтобы на пике нагрузок сайт работал не хуже, чем вне его.
Скорость генерации страниц нам будет интересна только в связке с другим показателем — объемом входящей нагрузки.
Обратите внимание: для сайта имеет значение только количество одновременных запросов, которые создаются пользователями, а не число online-пользователей на сайте. А подсчитать с приемлемой точностью количество запросов в секунду по количеству посетителей достаточно сложно (об этом я писал выше). Лучше запросить у бизнеса другие метрики – количество просмотров страниц в час и серверное время.
В итоге, мы получим понятную цель: обеспечить генерацию страницы за время X при количестве запросов в секунду Y. Имея на руках конкретные численные метрики, гораздо легче оценивать уровень готовности и текущий результат.
Вот общий план технической подготовки:
- Выяснить текущие показатели (провести нагрузочное тестирование текущей версии сайта);
- Разобраться, чего именно не хватает и сколько ресурсов требуется дозаказать;
- Добавить ресурсов;
- Повторить нагрузочное тестирование и убедиться, что помогло.
Выглядит слишком просто? Вы правы, каждый пункт таит в себе немало сюрпризов.
Очень часто добавление ресурсов частично улучшает ситуацию, но не спасает целиком. Или в тестовой среде сайт работает как часы, а на проде — снова тормоза.
Далее я расскажу, как выявить потенциальные проблемы и исправить слабые места. Начнем с того, как провести нагрузочное тестирование и получить реалистичный результат.
Проводим нагрузочное тестирование правильно

Где проводить тесты?
Часто нагрузочные тесты проводятся на продуктивной системе. Это может быть хорошо для контроля ситуации в целом, но не годится для итерационного решения конкретных проблем. Помните, обычно за вновь обнаруженными проблемами после устранения могут проявиться новые. Серебряные пули редко попадают в цель.
Проваленный нагрузочный тест может вызвать неудобства у пользователей сайта или даже «сломать» его на какое-то время. Лучше всего использовать в качестве подопытного кролика специально выделенную зону.
Она должна отвечать следующим требованиям:
- Выделенная зона должна быть полностью независима и изолирована от продуктива;
- В идеале, выделенная зона должна соответствовать продуктиву по размеру. Масштабная модель тоже подойдет, но это снизит качество и показательность тестов. Если нагрузка на какой-то ресурс растет нелинейно (как обычно и бывает), ваша модель не покажет, что под полной нагрузкой ресурс исчерпывается раньше времени;
- Лучше всего для тестов использовать точно такое же (но не то же самое!) оборудование, что и на проде. Иначе даже при соблюдении количественных значений ресурсов не получится обеспечить качественное. Это может сыграть злую шутку в самый ответственный момент. Если такой возможности нет, протестируйте показатели оборудования под вашей нагрузкой и определите коэффициент для корректировки.
Теперь поговорим о способах генерации тестовой нагрузки. Я приведу несколько основных методик, у каждой из которых есть свои плюсы и минусы.
Как генерировать нагрузку?
1. Тестируем по запросам из логов
Вполне возможно эмулировать поток трафика по логам боевых серверов. Очевидный плюс такого подхода – не придется заморачиваться с аналитикой, статистическим моделированием и синтетическим профилем трафика.
Но все равно придется чистить логи от запросов, которые делать нельзя или не нужно.
К примеру, не надо «покупать» товар на продуктиве, это вызовет проблемы с товарным наполнением базы.
Сложно будет воспроизвести реалистичные задержки между запросами.
Эмулировать пользовательские сессии также крайне трудно, этот метод очень близок к hit-based тестированию.
2. Использование Яндекс.Танка и Phantom
Танк в связке с Phantom — очень удобный и популярный инструмент для hit-based тестов. Он обладает продуманным интерфейсом и позволяет управлять нагрузкой. Чтобы начать обстрел из Танка, вы должны подготовить «патроны» — специальные файлы, содержащие запросы для генератора.
Но, несмотря на всё удобство, Танк имеет крупный недостаток: он не умеет в пользовательские сессии.
Можно забыть об авторизации, о полноценной работе с cookies и о переменных задержках. Танк может только «долбить» запросами с одного адреса.
Он подойдет вам, если:
- Нет разницы во времени ответа сервера для авторизованных и неавторизованных пользователей, или она пренебрежимо мала;
- Тестируется API без HTTP сессий в явном виде;
- Такой подход в целом соответствует логике работы вашего сайта (обычно не подходит для интернет магазинов).
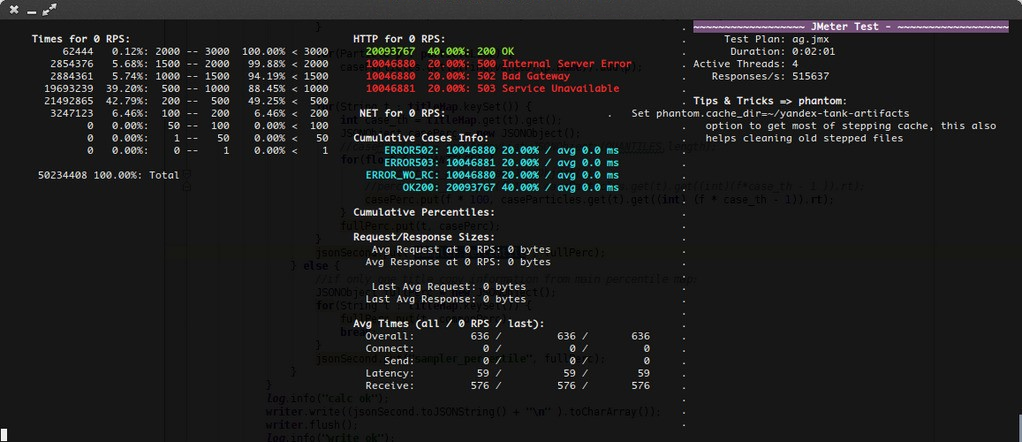
3. Использование Apache JMeter
Это наиболее гибкий инструмент, позволяющий детально эмулировать пользовательские сессии. А значит, с его помощью таки можно ответить на вопрос бизнеса «сколько пользователей выдерживает сайт?». К тому же, JMeter умеет работать в паре с Яндекс.Танком.
Его ключевой минус – ресурсоёмкость и трудоёмкость подготовки тестов.
Основной совет непосредственно по JMeter: постарайтесь избежать парсинга тел страниц его силами, лучше использовать заранее подготовленные наборы данных для воспроизведения логики сессий. В принципе, лучше вообще минимизировать работу, производимую JMeter’ом. Как и Танку, ему можно подложить заранее сгенерированные «патроны». Вот в них и нужно учитывать распределение конкретных страниц внутри одного типа, вариативность запросов и все такое прочее.
В самом JMeter нужно программировать именно модели поведения пользователей. Если стоит задача протестировать не только серверную часть, но и отдачу статического контента, запустите этот тест отдельно с помощью Phantom, при необходимости одновременно с тестом JMeter. Это поможет многократно сократить ресурсоемкость генератора нагрузки и повысить воспроизводимость теста.
Рекомендации по нагрузочному тестированию
В основе хорошего нагрузочного тестирования лежат грамотный анализ трафика и качественная подготовка статистической модели и профилей для эмуляции.
Выделите 5-7 основных типов страниц (не забудьте также про лендинги для акций), посчитайте, в каком процентном соотношении распределяется между ними общий трафик. Учтите при этом, что на одну страницу может приходиться несколько запросов к динамическому контенту. Для вас страница — это вся группа таких запросов. Проанализируйте, сколько времени пользователи проводят на странице каждого типа: в среднем, средний минимум, средний максимум.
Если страничка строится по нескольким запросам, учтите задержку между ними. Посмотрите, сколько страниц обычно посещает пользователь за сеанс, каково распределение этого количества. Выделите 5-10 наиболее типичных путей пользователей по типам страниц.
Используя полученные данные, постройте сценарии так, чтобы предельно точно воспроизвести все описанные статистические параметры. Не забудьте про вариативность сценариев, они должны различаться и по количеству, и по составу кликов.
Внутри каждого типа страниц выделите отдельные адреса. Чем больше, тем лучше, но пары-тройки тысяч самых популярных адресов уже будет за глаза. Из них можно подготовить списки запросов, добавляя каждый из адресов в список нужное количество раз.
Если страниц получилось слишком много, разделите их на несколько групп согласно проценту трафика.
Профили играют роль только для JMeter, но, построив списки запросов, вы можете снаряжать «танковые» патроны.
И еще раз: при использовании JMeter в режиме эмуляции пользователей не забудьте про задержки между запросами. Если их не добавить, ваша сгенерированная нагрузка будет многократно превышать планировавшуюся!
После пробного запуска обязательно посчитайте по логам web-сервера, соответствует ли эмулированный трафик продуктивному.
Высшим пилотажем будет заранее подготовить скрипты для приведения базы данных сайта к нужному вам состоянию. Обычно подготовленные вышеописанным образом данные работают только с тем состоянием базы, для которого собиралась информация по товарам. Перезаливать каждый раз SQL-дамп может оказаться непозволительно долго. Кроме того, очень желательно научиться управлять запущенными акциями с помощью скриптов на тестовой зоне. Зачастую они важны для работы системы, и вам нужно понимать, при каком наборе и как именно работающих акций проходит тестирование.
Всё готово? Отлично, полный вперёд!
Используем мониторинг в тестах

Итак, мы провели грамотное тестирование и получили результаты. Если всё хорошо, и ваш сайт справляется с высокой нагрузкой, то никакая Черная пятница вам не страшна. Но эта статья была бы неполной, если бы мы не рассмотрели печальный реалистичный сценарий.
Представим, что сайт может с приемлемой скоростью выдерживать...ну, пусть даже пятую часть от того, что хочет получить бизнес. Неужели придется в панике звонить хостеру и заказывать в пять раз больше мощностей?
В принципе, хостеру такой подход понравится. Возможно, вы даже получите статус золотого клиента.
Но прежде чем действовать опрометчиво, давайте попробуем разобраться, что именно пошло не так.
Ваш спасательный круг в море возможных причин — система мониторинга.
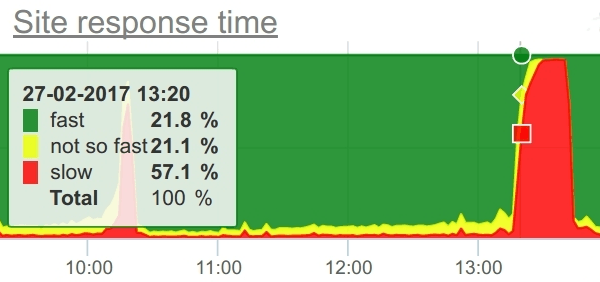
Поэтому сделаем шаг назад и перед тестированием установим как можно больше проб. В идеале, мониторить нужно все исчерпаемые ресурсы.
Приведу ниже список, который поможет вам начать:
- Загрузка процессора (CPU Usage, CPU Load);
- Загрузка оперативной памяти;
- Загрузка дисков (IOPS, Latency);
- Количество сетевых соединений (Time wait, Fin wait, Close wait, Established);
- Количество открытых сокетов;
- Количество пользовательских процессов;
- Количество открытых файлов;
- Сетевой трафик (в мегабитах и в пакетах, плюс ошибки и дропы).
А также:
- Количество запросов, ответов и соединений с БД и другими компонентами;
- Скорость ответа компонентов (база данных, поисковый сервер, кеши и т.д.);
- Все имеющиеся логи на предмет ошибок.
По всем этим параметрам вы должны знать имеющиеся лимиты. Это позволит в ходе нагрузочного тестирования понять, где именно образовалось «бутылочное горлышко». Не забывайте, большая часть этих «ресурсов» поддается конфигурированию, некоторые вообще управляются настройками.
Возможно, хватит пары мелких правок, и показатели улучшатся.
Где-то понадобятся не количественные, а качественные изменения: например, замена HDD на SSD. Ряд советов по оптимизации и масштабированию веб-приложений, а также повышению отказоустойчивости можно подсмотреть в моей предыдущей статье.
Также перед заказом ресурсов я рекомендую вам сравнить график роста нагрузки на систему с графиком её загруженности. Вовсе не обязательно там будет линейная зависимость.
Еще один совет: помните, мы говорили, что пользователи не умеют долго ждать? Если вы и бизнес договорились, что время генерации страницы, условно, более 2-х секунд абсолютно неприемлемо и такого пользователя можно считать ушедшим, пропишите тайм-аут (например, в 0,5 секунды) на соединение с бэкэндом и 1,5 секунды отведите на ответ. В случае более длительной загрузки можно отдать пользователю страницу об ошибке или заглушку а-ля «Опаньки, попробуйте еще раз».
На бэкенде можно установить максимальное ожидание от БД в 1 секунду, и так далее. Такая механика позволит не подавать нагрузку на компонент, который уже не успевает. Соответственно, вы снизите общую нагрузку на систему и предохраните её от долговременной перегрузки и отказа. В конечном итоге, тактика предоставления качественной работы (а не попытка выдать ответ любой ценой) значительно снижает количество пользователей, сталкивающихся с проблемой.
Заказываем оборудование
После того, как вы обнаружили зоны, которые нужно масштабировать, можно заказывать оборудование.
Если вы заказываете много «физического» железа, держите в уме сроки поставки. Они составят примерно 2-3 месяца, плюс еще месяц уйдет на тестирование, монтажные работы и настройку.
Заказывая много ресурсов в облаке, помните: не вы одни собрались переживать там Черную пятницу. Предупредите хостера за несколько месяцев, чтобы вам оборудования точно хватило. Облака, конечно, эластичны, но когда налягут все и сразу, может получиться конфуз.
Ещё дальновиднее будет заказать процессорные мощности в облаке с некоторым запасом. В период акции у многих провайдеров повысится загруженность физических ресурсов. За рамки, прописанные в SLA, они, вероятнее всего, не выйдут, но работать железо может несколько медленнее, чем во время тестирования в «спокойный» период.
Не забывайте про средства обеспечения информационной безопасности. Мало кто держит их не только в продуктиве, но и в тестовой зоне. Им тоже может не хватить ресурсов.
Не забывайте и о том, что любое, даже самое полезное вмешательство в работу системы может пошатнуть ее стабильность. Нельзя откладывать добавление ресурсов на последний день, оставьте себе хотя бы пару недель, чтобы успеть всё проверить и выловить последних барабашек.
После модернизации необходимо повторить тесты и убедиться, что сайт держит нагрузку. Во-первых, процесс добавления ресурсов может оказаться итеративным (могут всплыть новые потребности), а во-вторых, человеческий фактор тоже никто не отменял. Даже опытный спец может допустить косяк при инсталляции или провести неточные расчеты.
Пожалуй, на этом всё. Мы рассмотрели наиболее важные аспекты подготовки веб-приложений к большому объему трафика, популярные методы нагрузочного тестирования и способы выявления узких мест на этом этапе.
Если у вас появились вопросы, приглашаю их задать не только в комментариях, но и лично, на моём семинаре «Чёрная пятница в e-commerce. Секреты выживания», который пройдет 16 августа в Москве. Записаться на семинар можно тут.